Nonlinear relationship to solve XOR problem
This article explains the use of non-linear neural networks to solve the XOR problem, the method of parameter initialization, and the reason for using crossEntropy instead of MSE in classification problems.
First, the normal solution to the XOR relationship
import numpy as np
import matplotlib.pyplot as plt
x_data = np.array([[1,0,0],
[1,0,1],
[1,1,0],
[1,1,1]])
y_data = np.array([[0],
[1],
[1],
[0]])
# Initialize the weight, the value range is -1~1
v = (np.random.random([3,4])-0.5)*2
w = (np.random.random([4,1])-0.5)*2
lr = 0.11
def sigmoid(x):
return 1/(1+np.exp(-x))
def d_sigmoid(x):
return x*(1-x)
def update():
global x_data,y_data,w,v,lr,L1,L2,L2_new
L1 = sigmoid(np.dot(x_data,v)) #The output 4*4 matrix of the hidden layer
L2 = sigmoid(np.dot(L1,w)) #The actual output of the output layer 4*1
# Calculate the error of the output layer and the hidden layer, and then find the update amount
#
L2_delta = (L2-y_data) # y_data 4*1 matrix
L1_delta = L2_delta.dot(wT)*d_sigmoid(L1)
# Update the weights from the input layer to the hidden layer and the weights from the hidden layer to the output layer
w_c = lr*L1.T.dot(L2_delta)
v_c = lr*x_data.T.dot(L1_delta)
w = w-w_c
v = v-v_c
L2_new = softmax(L2)
def cross_entropy_error(y, t):
return -np.sum(t * np.log(y)+(1-t)*np.log(1-y))
def softmax(x):
exp_x = np.exp(x)
sum_exp_x = np.sum(exp_x)
y = exp_x/sum_exp_x
return y
if __name__=='__main__':
for i in range(1000):
update() #Update weights\
if i%10==0:
plt.scatter(i,np.mean(cross_entropy_error(L2_new,y_data)))
plt.title('error curve')
plt.xlabel('iteration')
plt.ylabel('error')
plt.show()
print(L2)
print(cross_entropy_error(L2_new,y_data))
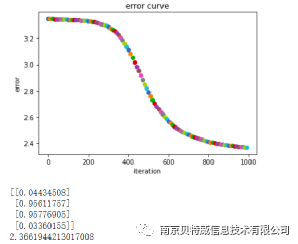
Let's talk about the input data x first: the first column is the bias item is always set to 1, and the last two columns are x1, x2 respectively. And y is the output corresponding to x1, x2, that is, the label of the result of the XOR relationship. lr is the set learning rate. Loss is calculated by cross-entropy. Finally, the prediction result below the figure is obtained, and it is not difficult to see that the prediction result is still very close to the label .
2. Use a linear relationship to solve the XOR problem
import numpy as np
import matplotlib.pyplot as plt
x_data = np.array([[1,0,0],
[1,0,1],
[1,1,0],
[1,1,1]])
y_data = np.array([[0],
[1],
[1],
[0]])
# Initialize the weight, the value range is -1~1
v = (np.random.random([3,4])-0.5)*2
w = (np.random.random([4,1])-0.5)*2
lr = 0.11
def update():
global x_data,y_data,w,v,lr,L1,L2,L2_new
L1 = np.dot(x_data,v) #The output 4*4 matrix of the hidden layer
L2 = np.dot(L1,w) #The actual output of the output layer 4*1
# Calculate the error of the output layer and the hidden layer, and then find the update amount
#
L2_delta = (L2-y_data) # y_data 4*1 matrix
L1_delta = L2_delta.dot(wT)
# Update the weights from the input layer to the hidden layer and the weights from the hidden layer to the output layer
w_c = lr*L1.T.dot(L2_delta)
v_c = lr*x_data.T.dot(L1_delta)
w = w-w_c
v = v-v_c
L2_new = softmax(L2)
def cross_entropy_error(y, t):
return -np.sum(t * np.log(y)+(1-t)*np.log(1-y))
def softmax(x):
exp_x = np.exp(x)
sum_exp_x = np.sum(exp_x)
y = exp_x/sum_exp_x
return y
if __name__=='__main__':
for i in range(300):
update() #update weights
if i%10==0:
plt.scatter(i,np.mean(cross_entropy_error(L2_new,y_data)))
plt.title('error curve')
plt.xlabel('iteration')
plt.ylabel('error')
plt.show()
print(L2)
print("The final error size is: ",cross_entropy_error(L2_new,y_data))
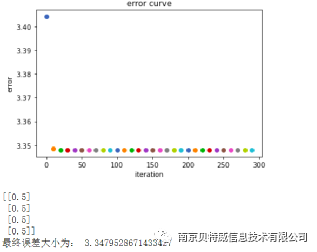
3. Use MSE as a loss function to solve the XOR problem
import numpy as np
import matplotlib.pyplot as plt
x_data = np.array([[1,0,0],
[1,0,1],
[1,1,0],
[1,1,1]])
y_data = np.array([[0],
[1],
[1],
[0]])
# Initialize the weight, the value range is -1~1
v = (np.random.random([3,4])-0.5)*2
w = (np.random.random([4,1])-0.5)*2
lr = 0.11
def sigmoid(x):
return 1/(1+np.exp(-x))
def d_sigmoid(x):
return x*(1-x)
def update():
global x_data,y_data,w,v,lr,L1,L2,L2_new
L1 = sigmoid(np.dot(x_data,v)) #The output 4*4 matrix of the hidden layer
L2 = sigmoid(np.dot(L1,w)) #The actual output of the output layer 4*1
#
L2_delta = (L2-y_data)*d_sigmoid(L2) # y_data 4*1 matrix
L1_delta = L2_delta.dot(wT)*d_sigmoid(L1)
# Update the weights from the input layer to the hidden layer and the weights from the hidden layer to the output layer
w_c = lr*L1.T.dot(L2_delta)
v_c = lr*x_data.T.dot(L1_delta)
w = w-w_c
v = v-v_c
L2_new = softmax(L2)
def softmax(x):
exp_x = np.exp(x)
sum_exp_x = np.sum(exp_x)
y = exp_x/sum_exp_x
return y
if __name__=='__main__':
for i in range(1000):
update() #Update weights\
if i%10==0:
plt.scatter(i,np.mean((y_data-L2)**2)/2)
plt.title('error curve')
plt.xlabel('iteration')
plt.ylabel('error')
plt.show()
print(L2)
print(np.mean(((y_data-L2)**2)/2))
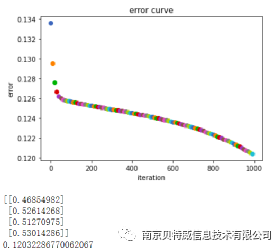
It is not difficult to see that using MSE cannot solve the XOR problem, so what is the reason?
Theoretically it would be possible to use the squared loss function for classification problems as well, but it is not suitable. First, minimizing the squared loss function is essentially equivalent to a maximum likelihood estimate under the assumption that the error follows a Gaussian distribution, whereas most classification problems do not have a Gaussian distribution. Moreover, in practical applications, the cross entropy, in conjunction with the Softmax activation function, can make the larger the loss value, the larger the derivative, and the smaller the loss value, the smaller the derivative, which can speed up the learning rate. However, if the squared loss function is used, the larger the loss, the smaller the derivative, and the learning rate is very slow. Look at the picture below to see the problem.
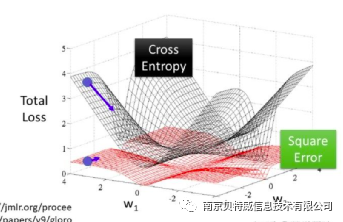
Look at the first result graph above and the third chapter result graph:

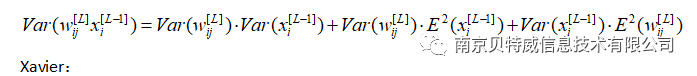
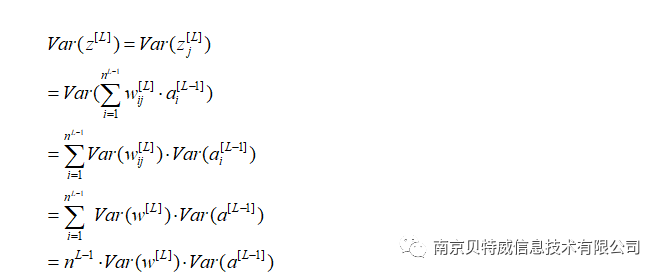
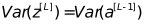
then need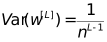
In backpropagation, the same
need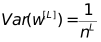
Take the harmonic mean of these two numbers: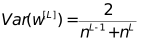
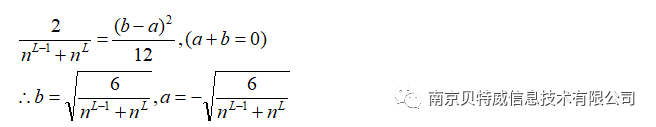
(a, b) is the range of initialized weights.
In this example, the number of neurons in the hidden layer is 4, so the weight initialization range can be approximately set to (-1,1).