background
The vacation business occupies a very important position in the entire online travel market, and how to make this cake bigger is the focus of the industry. Unlike food or hotels where the user’s points of interest are clear (such as finding a certain restaurant or a hotel near a certain destination), the user’s points of interest in travel scenarios (such as where to go on weekends) are difficult to determine, and will change with time. It varies with seasons, weather, user attributes, etc. These characteristics lead to the fact that traditional information retrieval cannot meet the needs of users very well, and we urgently need to build a travel recommendation system (vacation = travel in this article).
The travel recommendation system mainly faces the following challenges:
-
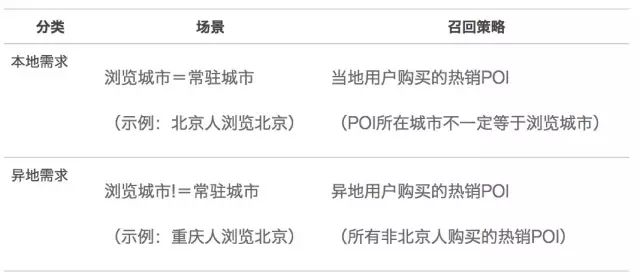
There are big local differences. In the local life scenario, most of the user's needs are concentrated locally, while in the travel scenario, more than 30% of the orders come from off-site requests, that is, users who live in city A have purchased travel orders in city B. It is no problem for foreigners to recommend the Forbidden City and the Great Wall when browsing Beijing, but it is more appropriate for Beijingers to recommend Beijing Happy Valley and Wildlife Park.
-
There are various forms of recommendation. In addition to the recommendation of scenic spots, there are also recommendations for group tours and wine packages. There are a large number of duplicate and similar tickets under the scenic spots, which are not suitable to be displayed in the style of Deal (group purchase order); group tours and scenic wine packages are generally bound to multiple scenic spots, and they are not suitable to be displayed in the style of POI (stores).
-
Seasonal is evident. For example, hot springs and skiing are more popular in winter, and more people choose water parks in summer.
-
Personalization of needs. For example, the needs of parent-child users and couple users will be different. Further subdivision, the needs of parent-child users aged 1 to 4 and over 6 years old will also be different.
In response to the above problems, we have customized a complete recommendation system framework, including a recall ranking strategy based on machine learning, and a recommendation engine ranging from offline computing of massive big data to high-concurrency online services.
policy iteration
The strategies of the recommender system are mainly divided into two categories: recall and sorting. Recall is responsible for generating recommended candidate sets, and sorting is responsible for personalizing the results of multiple recall strategies. The iterative evolution process of recall and sorting strategies will be described in the following sections.
Iteration of recall strategy
We started the construction of the travel recommendation system at the end of 2015. At this time, the vacation business has an independent peripheral travel channel homepage, and the recommendation strategy of guessing that you like the booth is the responsibility of the platform, which cannot solve many problems in the tourism scene. The following sections describe in chronological order how various recall strategies can be used to address these issues.
Hot Selling Strategy 1.0
The strategy of the first version of travel recommendation is mainly based on the city's hot sales, which is different from the city's hot sales based on the city where the Deal is located. This version of the strategy is based on the user's resident city. The reason is that the distribution of tourism resources in different cities is different, and there are resources. Lack of (customer source), abundant tourism resources (supply), and the need for locals to travel to surrounding cities. That is, for each city, there is a corresponding "urban circle" Deal library. For example, there is no ski resort in Langfang, but users whose resident city is Langfang often buy ski resorts in Beijing. Therefore, when Langfang users browse the surrounding channels in the local area I will recommend ski resorts in Beijing from time to time.
In the specific implementation, the seasonal changes of tourism products are considered, and the sales volume gradually decays with time. Assuming that 4 weeks is a change period, the Deal score formula is: deal_score = ∑((count(payorder) * α ^ i), where count(payorder) refers to the number of paid orders on the corresponding date of the Deal, i refers to the number of days from the date, an integer from 1 to 28, α is the attenuation coefficient (<1), and the Deal score is the daily sales score within a certain period Sum.
According to the above formula, the Top N hot-selling deals can be counted for each city, and then the deals that are 200km away from the current browsing city can be filtered according to the POI associated with the deals. For example, it is not good to recommend Shanghai Disney tickets when browsing Beijing, and it is not suitable for surrounding tours. position.
At this stage, we also tried popular orders, low-priced orders, and new order strategies. New orders and low-priced orders are easier to understand, which is to give these deals a certain exposure opportunity. Hot deals are similar to hot deals. The statistics are based on deal browsing data. Deals recalled by hot deals are not much different from hot deals. However, since the recommended evaluation indicator is the visit purchase rate (payment UV/recommended UV), the effect of these strategies is not as good as the hot sale, and they are not launched.
In addition, I also tried to recommend recommendations based on time-based contexts, such as: distinguishing working days/non-working days, filtering weekend tickets from Monday to Thursday, and filtering weekday tickets from Friday to Sunday, but it went offline with the POI recommendation.
There are two main innovations in the strategy at this stage:
-
Based on the statistics of the user's resident city, it has broken through the restrictions of the city where the Deal is located, and can recommend tourism products in surrounding cities locally.
-
Through sales decline, the seasonal problem is basically solved.
Recommended POIization
There are usually multiple ticket types under each attraction, and there are usually multiple deals under each ticket type. For example, the tickets for the Forbidden City include adult tickets, student tickets and senior tickets. Under the adult ticket, due to different Deal suppliers There are multiple deals, and the prices and purchase limits of these deals may vary. If it is displayed in the Deal style, it is possible that both adult tickets and student tickets of the Forbidden City will be recommended. On the one hand, a large number of repeated similar deals occupy the recommended booths, and on the other hand, the deal summary information is long, which is not conducive to user decision-making. Therefore, in early 2016, the recommendation POI was launched. The first version of the POI solution was recommended based on the POI associated with the Deal, that is, the Forbidden City adult ticket is a hot-selling order, and the Forbidden City POI displayed is actually recommended. There are two problems with this scheme:
-
The recommended deals may come from the same POI, and POI needs to be deduplicated. If there are 30 recommended booths, the number of candidate recommended deals must be >=30, but there may be less than 30 after POIization.
-
The sales volume of POIs reversed by Deal is not accurate, and the actual sales volume of POIs requires more accurate statistical methods.
Therefore, in Q2 2016, the POI hot-selling strategy based on F-value was launched. F-value is a tracking method within Meituan Dianping. The value records the POI ID, and this tag is then carried all the way to the order, so that the POI attribution for each order can be calculated relatively accurately.
Hot Selling Strategy 2.0
The main problem of the hot-selling strategy of version 1.0 is that it only considers the local purchasing preferences of users who are resident in cities. In short, it only solves the problem of recommendation for Shanghai people when browsing Shanghai. Shanghai people recommend the same. Zooming in is a problem of the local remote scene. The definition of the local remote scene is shown in the following table. Version 2.0 of the hot-selling strategy counts local and remote orders separately. When a user visits Meituan, it first determines whether the user is a local or a remote user, and then recalls the corresponding POIs. Users who cannot get the resident city are regarded as local by default. ask. From the recommendation results, it can be seen that locals in Beijing love to go to Happy Valley, and foreigners who go to Beijing prefer to go to the Great Wall and the Forbidden City.
In this version, we continue to try the subdivision recommendation in the context of time, and count the distribution of orders in each hour of each day for a period of time. There are 3 saddle points, corresponding to dividing the day into 3 time periods: early, middle and late, divided into time periods. Statistics POI hot sale. From the perspective of recall, the POI ranking has changed a lot compared to the previous one, but due to the role of Rerank below, it has little impact on the overall recommendation.
Strong correlation strategy for user history behavior
Although the hot-selling strategy can distinguish the differences between local and remote users, it lacks personalized recommendation for a specific individual user, so a recommendation strategy that is strongly related to the user's historical behavior is introduced. Take the POIs that users have browsed, bookmarked and unpurchased in the last month, grouped by city, and de-weighted by POI ID. The higher the real-time weight, the higher the weight.
Location-based recommendation strategy
The above strategy either has a large amount of POI data or user data. If the user or POI has no historical behavior data or is relatively sparse, the above strategy will not work, which is the so-called "cold start" problem. In the mobile scenario, the device can obtain the user's geographic location in real time, and then make recommendations based on the geographic location. The specific recommended strategies are divided into two categories:
-
Find the POIs within a few kilometers of the user's real-time location and sort them by recent sales decline, and get the list of Top POIs.
-
Find user groups within a few kilometers of the user's real-time location, and recommend Top POIs based on their recent purchase behavior. For example, users are located in Huilongguan, and there is no POI near Huilongguan, but users in Huilongguan will buy some popular POIs in season.
The geographic location recommendation strategy needs to filter out the inconsistency between the city located by the user and the city selected by the client. For example, it is not suitable for users located in Beijing to recommend POIs around Beijing when browsing Shanghai.
Collaborative filtering strategy
Collaborative filtering is the most classic algorithm in recommender systems. Compared with strategies that are strongly correlated with historical behavior, it is equivalent to abstracting and generalizing user interests and POI attributes. Collaborative filtering algorithms are mainly divided into two categories: ItemCF and UserCF. We first implemented ItemCF. The main reasons are:
-
Performance: The number of POIs in Meituan is much smaller than the number of users. The core of the collaborative filtering algorithm is to maintain a similarity matrix (Item/User similarity). Maintaining the POI similarity matrix is much less expensive than maintaining the user similarity matrix;
-
Real-time: users have new behaviors, which will definitely lead to real-time changes in the recommendation results;
-
Cold start: As long as a new user acts on a POI, he can recommend other POIs related to the POI to him;
-
Interpretability: Use the user's historical behavior to recommend and explain the user, which can convince the user.
Collaborative Filtering Based on POI Browsing Behavior
The similarity between POIs is calculated according to the browsing data of the UUID dimension, and the browsing behavior is more dense than the ordering and payment behaviors. The time window takes one month's data. In theory, as long as the computing power is not a bottleneck, the time window should be as long as possible. The similarity formula is defined as follows:

The user's behavior table for POI is updated every day after offline production, which is equivalent to only the data before the day, and lacks feedback on the user's real-time behavior of the day. Therefore, the collaborative filtering recommendation based on the user's real-time POI behavior is added, and the POI similarity above is reused. Calculation results.
Collaborative Filtering Based on User Search Behavior
Search behavior is a strong intention behavior. Most travel orders come from search portals, and a considerable proportion of search users do not click on any POI. Recommendations based on user search behaviors can be used as a supplement to POI browsing recommendations. First, construct the similarity matrix of Query and POI, and use the POI structure that users browsed within 10 minutes after searching for Query.
The specific implementation uses Query+City as the key. The reason is that there are some national chain POIs in the tourism scene, such as Happy Valley and Fangte. If only Query is used as the key, the POI most related to the "Happy Valley" query may be " Beijing Happy Valley”, then users will recommend Beijing Happy Valley after searching for “Happy Valley” in Shenzhen, which does not meet the needs of users.
Similarity improvement
The above similarity calculation formula has two improvements: First, the sequence of user behaviors is not considered, for example, users browse POIs successively

Panoramic View of Recall Strategy
After a year of iteration, the current online recall strategy is shown in the figure below. In addition, the matrix decomposition based on ALS has been tried, but the recommended results are relatively unpopular and the interpretability is poor; and POIs are marked with corresponding attribute labels, and can be recommended directly with single-dimensional labels. For example, parent-child POIs can be recommended to parent-child users, and labels can also be used as dimensions to calculate the correlation between users and POIs in multiple dimensions.
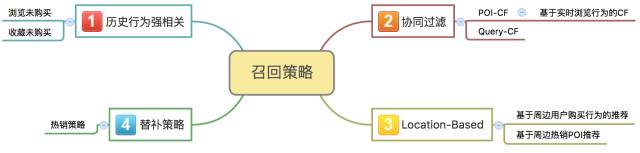
The results of each type of recall strategy need to be filtered. There are mainly several types of filtering strategies:
-
Blacklist filtering. For example, there is dirty data at the source or a case that requires manual intervention.
-
No POI filtering for sale. That is, filter POIs that do not sell deals.
-
POI distance filtering. Filter POIs hundreds of kilometers away from the current browsing city.
-
Non-current city filter. Filter POIs that are not currently browsing cities.
-
POI filtering has been purchased.
The first two types of filtering strategies are common to all recall strategies and need to be done. Blacklist filtering takes into account the real-time nature of data updates and is processed online. Other filtering strategies can be uniformly processed at the offline data layer. The last three categories are only required by specific recall strategies, because they depend on user requests and can only be processed online. The specific rules are as follows:

Sorting Policy Iteration
Each type of recall strategy will recall certain results, and these results need to be sorted uniformly after deduplication. In the early stage, when there was only one hot-selling strategy, there was no need to rerank, and the ranking was directly based on the hot-selling score. After adding the strong correlation of historical behavior and the Location-Based strategy, it was also displayed in fixed booths, such as: 1st, 3rd, 5th, and 7th. Give the historical behavior a strong correlation strategy, and the 2nd, 4th, 6th, and 8th bits are given to the Location-Based strategy.
At the beginning of Q1 2016, I tried the first version of the Rerank strategy. At that time, the recommended style was still Deal, so the sorting object was also Deal. The main feature was the sales/rating data of 30/180 days. Because there were few features considered, the effect after going online was not good. Not obvious.
At the beginning of Q2, because the POI display was basically completed, the sorting object became POI, and the main features included sales, ratings, prices, and refund data. The effect was still not obvious after the launch.
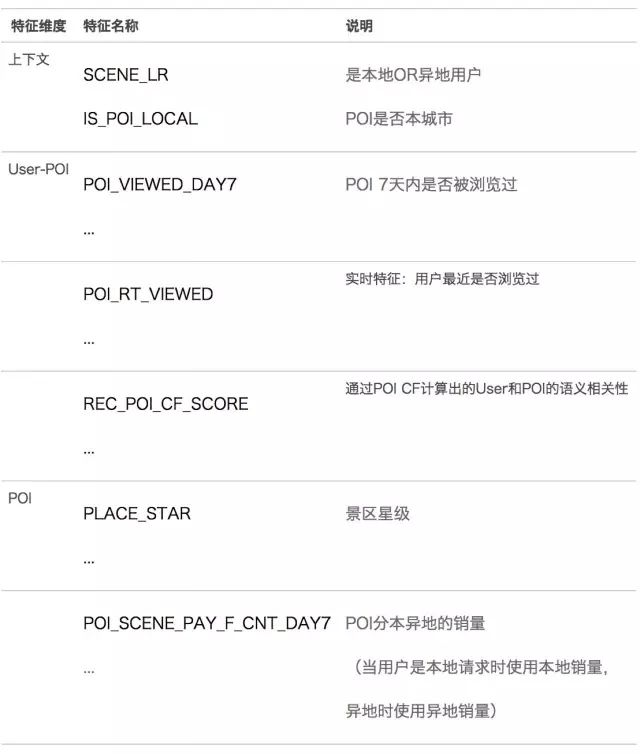
Because the recommendation list page is similar to the filter list page, I tried to directly access the screening Rerank in the middle of Q2, but the effect was not very satisfactory. Then, based on the recommended data samples, the training was re-trained, and some new features were added. The features are roughly divided into the following categories:
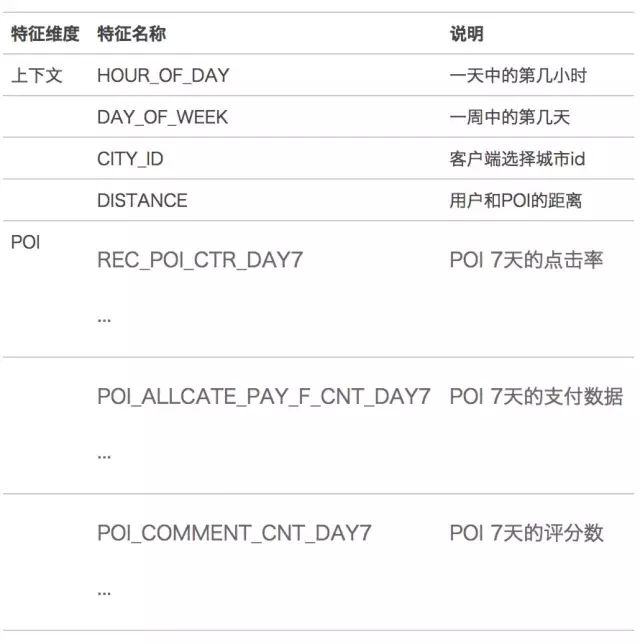
It can be seen from the above table that context features, distance features and shopping-related features are mainly added on the basis of sales and evaluation. It is noted that HOUR_OF_DAY, DAY_OF_WEEK, and CITY_ID do not use one-hot encoding, and the online experiment one-hot encoding effect is not effective. Better than using raw values directly. The possible explanation is that the discrete value of HOUR_OF_DAY can be used to classify the tree model, for example: 0~11:00 can represent the morning, 12:00~18:00 can represent the afternoon, 19:00~23:00 can represent the night; Similarly, DAY_OF_WEEK can be used from Monday to Thursday. It is considered to be weekdays, and Friday to Sunday is considered to be weekends; the possible explanation of CITY_ID is that the smaller the ID, the earlier the city opened, and the more popular the city.
In the model, the sample before the last click is taken as the candidate sample set, the payment is taken as the positive sample, the others are negative samples, and the sampling ratio of positive and negative samples is 1:10. If no sample sampling is performed, it is assumed that there is only one payment for every 100 people who visit the list page. It is assumed that users can see an average of 10 POIs per visit to the list page, that is, the ratio of positive and negative samples is about 1:1000, and the sample distribution is extremely unbalanced, which is easy to cause overfitting. The XGBoost algorithm is used for model training, and the click rate and visit purchase rate are obviously positive after going online, which proves the effectiveness of Rerank.
On the basis of the above, the context features have been gradually enriched. For example, the recall may trigger the POI of the surrounding city circle, so whether the POI is a feature of the city is added. In addition, the hot-selling recall strategy splits the local and different places, and Rerank also increases user requests accordingly. Whether it is a local feature or not; User-POI combination features have been added: whether the User has browsed/favored POIs within 7 days, real-time features, User-POI correlation based on collaborative filtering, etc., which are strongly related to historical behavior and collaborative filtering recall strategy can be Corresponding; added POI static attribute characteristics, such as: star rating, and also split the POI sales according to local and remote locations. After the launch of these features, the effects are basically positive and in line with expectations.
In the model, we tried the fusion of short-cycle model and long-cycle model. The short-cycle is the recent one-month data, and the long-cycle is the recent three-month data. From the online results, the short-cycle model is the best, which may be related to the fast seasonal changes in tourism. In addition to the above features, user personalized features, weather context features, POI features, and CTR/CVR can be split into local and remote locations.
Sorting Strategy Panorama
The recommended offline training process is consistent with the search and filter sorting. The flow chart is as follows:

-
The first is data labeling. The data source is the original sample log, which is recorded in Hive, and the output is an ISample object with a label. In addition, some features may need to be produced online and written into the sample log, such as: real-time features, which cannot be collected by offline ETL;
-
Sample selection: filter the initial sample, for example: filter the data after the last click sample, the output is still ISample;
-
Feature extraction: There are POI IDs in the samples. According to the POI IDs, the sales, evaluation and other features of the POIs can be extracted; similarly, the user-related features can be extracted according to the UUIDs in the samples. This generates a Sample with Feature;
-
Data sampling: abstract samples according to a predefined positive and negative sample ratio;
-
Training Set Construction & Output: Output the training set in XGBoost format.
The construction process of the entire training set is written in Scala and runs on the Spark cluster. Since the Spark version of XGBoost is not very stable, the single-machine version of XGBoost used in the final model training and evaluation, the training parameters of the model (the number of iterations, tree Generally, the empirical value is selected, the training set is selected from one month of data, and the test set is generally selected several days after the date of the training set. The offline evaluation index mainly refers to AUC.
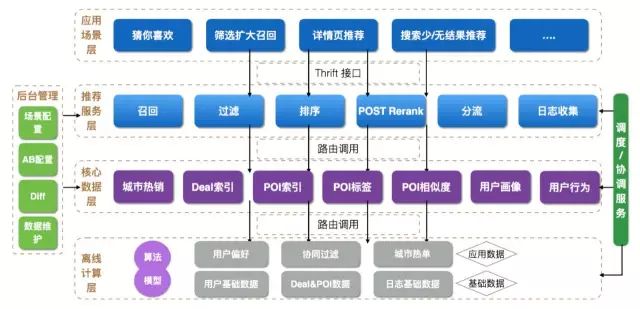
Engineering Architecture Design
The overall engineering architecture of the recommendation system is shown in the figure below. From bottom to top, it includes the offline computing layer, the core data layer, the recommendation service layer and the application scenario layer, as well as the background configuration management system and data scheduling service.
Offline computing layer
In addition to the features and training logs required by Rerank, the offline computing layer mainly includes basic data and application data. The most important of the basic data is the data of Deal and POI. In order to ensure the accuracy and real-time nature of the data, the data of Deal and POI are directly obtained from the tourism product center, and the full amount is pulled regularly and updated in real time with the addition of message queues. Application data can be divided into three categories according to the production method:
-
Data produced by Hive ETL: such as offline tables (logics such as main stores) that need to be used for POI filtering, and the other category is statistical data, such as: hot sales of POIs in cities, hot sales of line tours, users’ browsing/purchasing behaviors of POIs .
-
Data produced by Spark: for example: User CF, POI CF, matrix factorization algorithm, etc. The production logic of this kind of data is complicated, and it is not easy to complete it directly through ETL calculation.
-
Data produced by Storm: User real-time behavior is needed for recall and sorting. Currently, the company provides a unified real-time user behavior data stream user__action_basic, including: browse/collect POI/Deal, order, payment, consumption, refund, and filter from it The behavior of traveling POI/Deal can be done.
core data layer
An important reason for abstracting the core data layer is the need to reuse DataSet for offline computing engineering and online service engineering. From the perspective of storage methods for online use, it can be divided into three categories:
-
Data stored in ElasticSearch (hereinafter referred to as ES). Mainly POI/Deal index, such as: POI's geographic location, city, ES query can be used when online needs to be filtered according to geographic location, such as: distance limit of city circle, Location-Based strategy recall within a certain distance. In addition, ES is more suitable than KV storage for multi-dimensional query scenarios. This type of data is scheduled regularly through the company's unified task scheduling system, usually updated every few hours. Here, an alias is established for the ES index, and the index is updated offline to cut the pointer of the alias to ensure the atomicity of the operation.
-
Data stored in DataHub. DataHub is a data management system developed by the wine travel search team, which integrates data storage, management and use. Currently, data from Hive tables can be imported regularly. DataHub mainly uses Tair as storage, which is transparent to the client. The client interface supports one-dimensional and two-dimensional keys. The interface is basically the same for the application side, and the application side does not need it. Maintain Tair cluster configuration management by yourself. DataHub has its own scheduling function, which automatically writes to Tair after it is generated by scanning HDFS partitions.
-
直接存储在Tair中的数据。主要面向DataHub还不支持的两类场景,一是实时数据的存储落地,二是value直接存储对象,存储为对象的好处是从Tair读取出来的对象可直接供线上使用,无需自行序列化和赋值。实时数据无需定时调度,通过Spark直接写入Tair的数据通常需要依赖上游Hive表先Ready才能执行,所以通过公司统一的数据协同平台调度。
推荐服务层
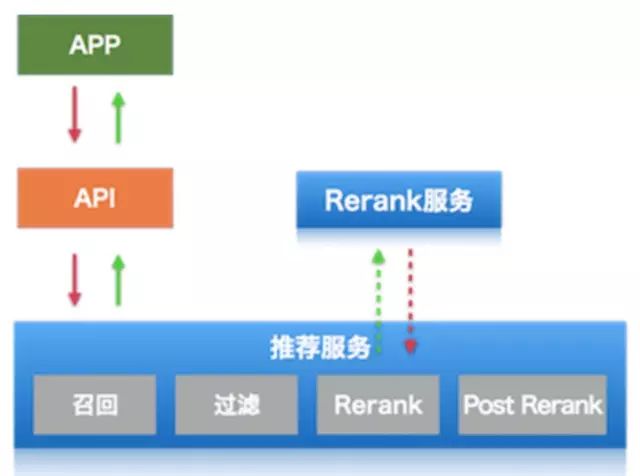
服务上下游
推荐上下游的架构图如下图,客户端向API发起调用,API调用推荐服务拿到推荐的ID再添加供App展示用的相关字段传会给App。推荐和搜索没有整合成一个服务的重要原因是推荐的召回策略复杂多样,每次请求可能命中多个召回策略,而搜索单次请求的意图一般比较单一,通常只有一个召回策略。另外推荐服务重点在召回和过滤,Rerank调用独立的rank服务,原因是推荐Rerank和搜索筛选Rerank在特征上有很多是可以复用的,比如:用户特征、POI特征等。
整体流程
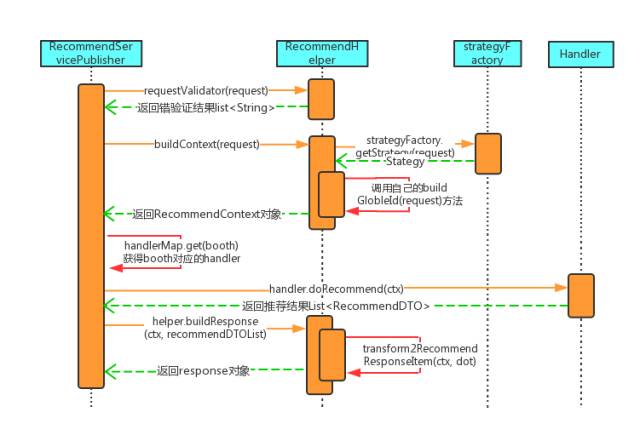
推荐服务向下从数十个数据源中获取数据,经过业务逻辑处理后向上支持数十个应用场景,整个调用流程如下:
-
RecommendServicePublisher作为服务的入口,从Client接到Request请求后首先验证请求是否合法,比如:请求参数中场景Booth和UUID不能为空。
-
构造请求上下文Context,其中会生成唯一的global ID标识一次请求,根据UUID查询用户画像服务获取常驻城市,根据定位的经纬度查询定位城市,以及根据ABTest分流配置获取处理请求的召回排序Strategy。
-
根据请求场景的Booth获取对应的Handler,默认使用统一的AbstractHandler即可,包括召回、过滤、rerank、post rerank。
-
对Handler返回的结果做包装,增加召回和排序策略名称、得分等,最终返回给Client。
核心流程与模型
Handler是整个流程的核心,其调用流程如下:

-
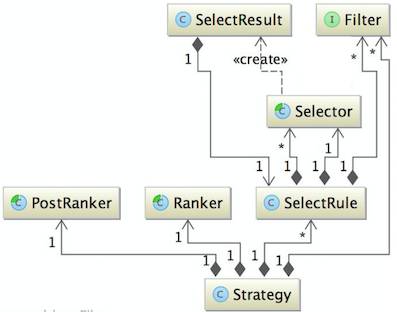
Handler根据不同的Strategy获取对应的SelectRule集合,一个场景Booth可能对应多个Strategy,跟ABTest对应,比如:Baseline就是一个Strategy。每个Strategy可能有多个SelectRule,比如:Baseline策略由历史行为强相关SelectRule、Location-Based SelectRule、热销Rule等组成。
-
召回:每个SelectRule又对应多个Selector,多个Selector通过线程池并发获取结果,比如:Location-Based Rule可以细分为基于周边热销POI召回和基于周边用户购买POI召回。Selector可再做抽象,比如:分本异地场景的城市热销策略,美团和点评双平台都需要,只是数据源稍有不同,另外对于从ES和DataHub获取的数据可以加Cache。
-
Merge去重:多个召回策略的结果需要Merge去重,比如早期没有Rerank时Location-Based策略固定在2、4、6位。
-
过滤:具体有两级过滤,一级是针对SelectRule的,比如:针对历史行为强相关策略中基于浏览行为和收藏行为召回的结果都需要过滤用户已购买过的POI;另一级是针对所有策略通过的过滤,比如黑名单、旅行社代理商。
-
重排序:对于POI列表调用POI Rerank服务,对于Deal列表调用Deal Rerank服务。
-
PostRerank:一般用于处理广告运营的需求和人工干预的Case。
核心的对象模型如下图:
监控降级
监控分为离线监控和实时监控两部分,离线监控使用Falcon来监控以下几类指标:
-
JVM监控:比如FullGC次数、内存使用情况、Thread block情况
-
ES监控:ES查询次数和平均响应时间
-
业务监控:各接口、各策略的请求次数和平均响应时间
实时监控接入公司统一的实时数据统计平台,可以分时、分多粒度统计各Booth的请求次数和响应时间。
降级主要通过Hystrix来实现,比如:调用Rerank服务在一定时间内响应时间超过设定的阈值,则直接熔断不请求Rerank服务。
工具化
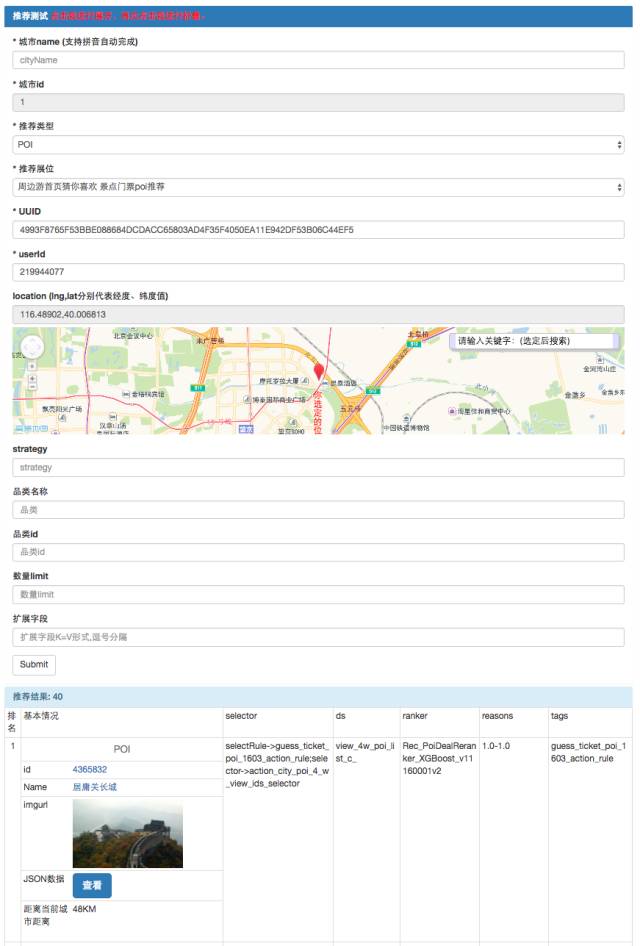
推荐服务开发了Debug工具,输入支持城市、展位、UUID、经纬度等参数,输出展示了POI/Deal的头图、标题、和用户的距离、召回排序策略与得分等。方便PM和RD测试、定位追查Case。
应用场景
推荐系统支持了美团/点评共20个应用场景,主要场景是周边游频道首页猜你喜欢,其召回策略在上文中已有阐述,这里重点阐述其他几类推荐场景:
跟团游推荐
跟团游Deal一般会绑定多个景点,不适合按POI样式展现,因此采用Deal形式展现,召回策略跟热销POI策略类似,区分本异地,从结果看北京本地人会推荐“古北水镇一日游”,外地人浏览北京时会推荐“故宫、长城一日游”。
筛选异地召回
用户在筛选酒店时会先选择入住城市再筛选该城市的酒店POI,而周边游存在客源地旅游资源不丰富的问题,筛选时需要突破选择城市限制,能够推荐出周边城市的热门POI,筛选异地召回上线后增加了一定比例的订单,是对本地召回的有效补充。
筛选主题标签挖掘
即为POI打标签,用户可以用这些标签进行筛选,比如:附近热门、近郊周边、周末去哪、亲子同乐、夜场休闲。每个标签都可以定义一套挖掘方法,比如:“亲子同乐”有以下几类方法:
-
POI下有亲子票种
-
Deal标题包含“亲子”
-
同一POI下同时包含“成人票”和“儿童票”
-
用户画像为“亲子”的用户最近一个月购买的POI
上述挖掘方法偏规则,后续希望能通过半/无监督方法,挖掘POI描述和评论,自动为POI打标。
搜索少/无结果推荐
搜索少结果推荐是指当搜索结果POI类聚结果数=1时,为丰富页面内容给用户提供推荐信息。这里重点利用搜索的POI结果根据POI CF触发推荐,以及利用搜索POI的品类进行同城市同品类推荐。
搜索无结果推荐可以直接统计搜索Query后一定时间内用户浏览的POI做推荐,但这个策略的覆盖面有限,进一步可以计算一段时间内的Query CF,然后做协同推荐;另一方面可以通过意图识别判断Query中是否有品类词,触发同品类推荐。
酒旅交叉推荐
目前只实现了酒店和旅游之间的交叉推荐,当用户在酒店频道搜索时先判断Query是否旅游意图,其中重点分析两类意图:一是景点POI意图,推荐该景点几公里范围内的POI;二是品类意图,比如:温泉、滑雪,会推荐用户定位附近该品类的热销POI。
在酒店POI详情页会获取酒店POI的地理位置,推荐酒店附近的景点。对于异地用户浏览酒店时都会触发景点推荐,对于本地用户只有在浏览郊区酒店时会触发旅游推荐,这是假设本地用户在浏览市区酒店时旅游度假的意图可能不明显。
除了在各类推荐场景的应用,这些策略在运营上也有应用尝试,比如:用户浏览或购买过POI后根据POI CF给用户PUSH相似的POI,实验证明推荐策略的PUSH点击率要高于平均水平。
未来的挑战
经过一年多的迭代优化,周边游频道内相当比例的订单来自推荐,线上支持了20个左右的推荐场景,很多推荐策略被作为特征加入搜索、筛选Rerank,有明显正向效果,在用户运营上也有了初步的探索。基于目前的推荐系统本身还有不少优化点:
-
召回策略:策略的广度和深度都有不少提升空间,广度方面可以继续探索矩阵分解FFM、User CF、基于用户画像的推荐、图挖掘;深度方面尝试LLR等多种相似度计算方法、以及多时间/多用户维度改进召回策略。数据上可以扩大到酒店甚至美团全平台的用户数据,另外对策略的离线实现还要更模块化、抽象化,比如:相似度改进算法在一处场景验证有效,可快速推广上线到其他场景
-
排序策略:特征工程方面可以增加User个性化特征、天气/Listwise上下文特征等,模型上可以尝试DNN等方法,评估指标可以从访购率改进成访消率(消费UV/访问UV),另外对美团/点评双平台可以定制不同的特征数据和排序策略
-
工程架构:搜索少/无结果推荐从搜索工程迁移到推荐工程,另外对核心数据层存储方式的边界划分,线上服务层的缓存、Selector/Rerank降级、Filter/Merge逻辑梳理等需要做“轻量重构”
-
应用场景:除了在酒店购买前的交叉推荐外还可以增加购买后的推荐,以及和机票、火车票大交通相关的交叉推荐,在旅游内部可以探索更多的场景化建设,比如:亲子游、情侣游
跳出目前单一的以POI/Deal列表为主体的推荐形态看,可以从用户、场景、内容、触达方式四个方面看如何做好旅游推荐:
用户需求
首先考虑用户是谁?要满足用户的什么需求?这里可以利用美团/点评的数亿用户,打“人群标签”,是一二线城市高端品质女用户、勤俭住宿的中年大叔还是三线城市实惠型年轻妈妈。然后分析这些人群背后的需求,是本地休闲用户、差旅用户还是高频度假用户,不同用户的需求是不一样的。
场景划分
当知道用户后需要知道用户的场景是什么?可以从四个维度定义场景:时间、位置、行为、渠道。

时间很好理解,当用户在周四周五搜索“滑雪场”,会被认为是休闲度假周末用户,可以协同推荐北京郊区的滑雪场。
地理位置是核心要素,要根据用户的常驻城市和客户端选择城市来判断是本地还是异地需求,对于异地的差旅用户可以推荐商务型的酒店。
行为是用户需求最直接的反应,比如:用户搜索“古北水镇”,不管用户后续是否有浏览行为,都可以推荐古北水镇相关的酒店和景点门票。
渠道包括美团/点评双平台App、i版、PC等多个终端,以美团App为例,周边游、酒店、机票/火车票频道的用户特征都不一样,比如:大交通频道最常见的是差旅用户、周边游频道更多是本地度假休闲的人群。
内容形态
知道了用户是谁以及处于什么场景,要考虑提供什么样的内容产品?对于美团来说核心是交易,内容不是最核心的目标,但内容是一个非常好的引流措施。以本地场景为例,可以加强场景建设,比如:亲子、团建、温泉等;异地行前场景可以加强目的地、点评游记攻略、酒店交通行程安排等内容建设。
触达方式
除了目前的搜索推荐外,还可以增加定向投放、内容引导、广告植入、活动运营等多种触达方式。
总之旅游推荐问题复杂多样,需要从度假出行六要素:吃、住、行、游、购、娱综合考虑和规划,对产品形态、业务策略、技术架构都还有很大的挑战和机遇。
作者简介
郑刚,美团点评高级技术专家。2010年毕业于中科院计算所,2011年加入美团,参与美团早期数据平台搭建,先后负责平台、酒旅数据仓库和数据产品建设,目前在酒旅事业群数据研发中心,重点负责酒店旅游场景下的搜索排序推荐、数据挖掘工作,致力于用大数据和机器学习技术解决业务痛点,提升用户体验。
「 更多干货,更多收获 」
推荐系统工程师技能树
【免费下载】2022年6月份热门报告盘点
美团大脑系列之:商品知识图谱的构建及应用
大数据驱动的因果建模在滴滴的应用实践
联邦学习在腾讯微视广告投放中的实践
如何搭建一个好的指标体系?
如何打造标准化的数据治理评估体系?
【干货】小米用户画像实践.pdf(附下载链接)
推荐系统解构.pdf(附下载链接)
短视频爆粉表现指南手册.pdf(附下载链接)
推荐系统架构与算法流程详解
如何搭建一套个性化推荐系统?
某视频APP推荐策略详细拆解(万字长文)
关注我们

|
智能推荐 个性化推荐技术与产品社区 |
长按并识别关注
|
一个「在看」,一段时光👇