The exercises of some of the previous crawler projects actually only include simple web page requests and web page acquisitions. We have not implemented obtaining the specified information from the specified website, that is, there is no step of parsing the web page information. Generally speaking, there are three methods for web page parsing: RE regular expression matching, Xpath extraction, and Beautifulsoup third-party library parsing. Today, we focus on introducing RE.
RE (Regular Expression)
A regular expression describes a pattern of string matching, which can be used to check whether a string contains a certain substring, replace a matched substring, or extract a string that meets a certain condition from a string. substring, etc. The principle of using regular expressions to parse webpages is that all webpage codes can be regarded as long strings, and we can intercept the corresponding strings through content matching, so as to extract the required information.
Getting Started with RE
For the introductory tutorial of RE, you can go to the following website to practice.
-
The regular expression introductory course of programming capsule (https://codejiaonang.com/#/course/regex_chapter1/0/0) website has a very detailed introduction to regular expression matching, which is relatively basic, accompanied by corresponding web page exercises.
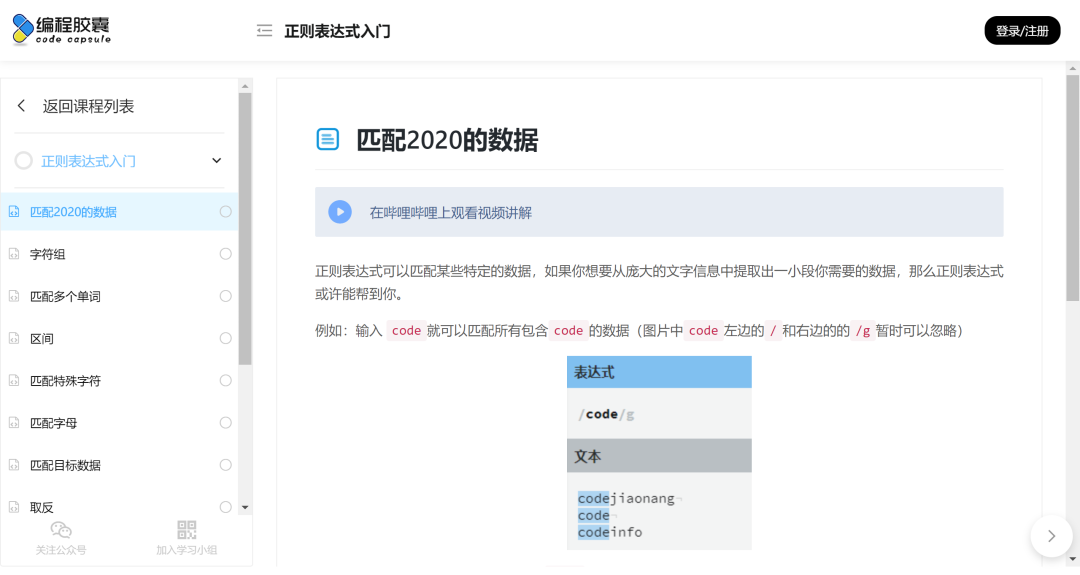
-
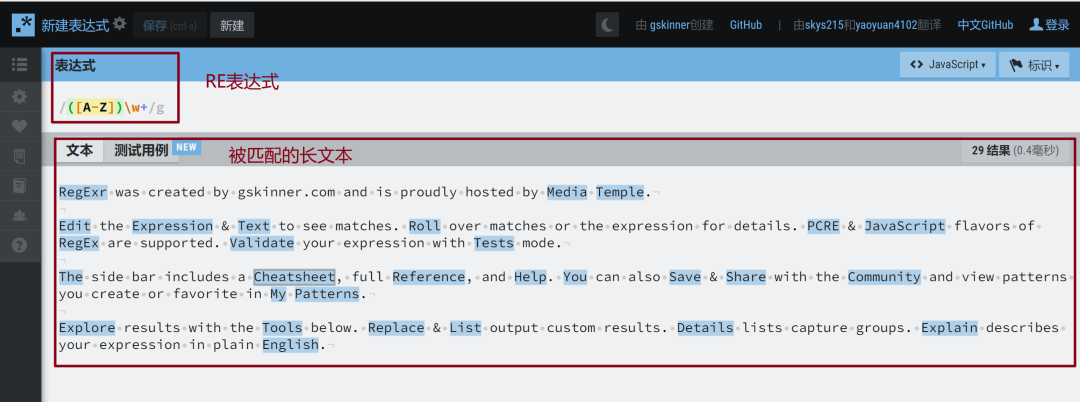
The regexr website (https://regexr-cn.com/ ) is a website for testing regular expressions. The expression is written above, and the matched text is placed below. The matching content will display blue shading.
Regular expressions commonly used by reptiles
The RE package is built into Python for web page parsing. Virtually all regular expressions will work in certain situations. Here we focus on the following regular expressions:
-
. any character -
* matches the preceding subexpression zero or more times. To match the * character, the escape character \* is required. -
? Match the preceding subexpression zero or one time, or specify a non-greedy qualifier. To match the ? character, you need to use the escape character \?
The regular expression constructed from these three special characters is as follows: -
Lazy match.*? Match as few characters as possible.
It will match as few characters as possible. It starts from the first character. Once the condition is met, it is immediately saved to the matching set, and then continues to search. So it's lazy. -
Greedy match.*
Match as much as possible It will match as many characters as possible. It first looks at the entire string, and if it does not match, it shrinks the string; when encountering text that may match, it stops shrinking and expands the text. When a matching text is found, it does not rush to save the match to the matching set , but continue to expand the text until it can no longer match or expand the entire string, and then save the last matching text (also the longest) in the matching set. So it is greedy. After finding a match, continue to search, if it finds an inappropriate one, return the last one that matches.
RE in python
import re #导入RE的包
Some commonly used syntaxes are:
re.findall The syntax is re.findall(pattern, string, flags=0), which returns all strings matching pattern in the string, and the return form is an array. flags : optional, indicating matching mode, such as case-ignoring, multi-line mode, etc. The specific parameters are:
-
re.I ignore case -
re.L means the special character set w, W, ., B, s, S depends on the current environment -
re.M multiline mode -
re.S is . and any character including newlines (. does not include newlines) -
re.U means special character set w, W, ., B, d, D, s, S depends on Unicode character attribute database -
re.X ignore spaces and comments after # for readability
lst = re.findall(r"\d+","电子商务专业有2个班70+个人")
print(lst)
# findall 匹配字符串当中所有的符合正则的内容
Return result:
['2', '70']
re.finditer returns all the strings in the string that match the pattern. The return form is an iterator. You need to use group() to get the content.
for i in re.finditer(r"\d+","电子商务专业有2个班70+个人"):
print(i.group())
Return result:
2
70
The re.search syntax is re.research(pattern, string, flags=0) will match the entire string and return the first successful match, you need to use group() to get the content.
lst = re.search(r"\d+","电子商务专业有2个班70+个人")
print(lst)
Return result:
<re.Match object; span=(7, 8), match='2'>
The re.match syntax is re.match(pattern, string, flags=0) to match a pattern from the starting position of the string. If the matching is not successful at the starting position, match() returns none.
lst = re.match(r"\d+","电子商务专业有2个班70+个人")
print(lst)
Return result:
None
lst = re.match(r"\d+","1个电子商务专业有2个班70+个人")
print(lst)
Return result:
<re.Match object; span=(0, 1), match='1'>
re.compile() generates a regular object, which is meaningless to use alone. It needs to be used in conjunction with findall(), search(), match()
obj = re.compile(r"\d+")
res = obj.finditer("电子商务专业有2个班70+个人")
for i in res:
print(i.group())
Return result:
2
70
txt = """
假如生命是一株小草,我愿为春天献上一点嫩绿;
假如生命是一棵大树,我愿为大地夏日撒下一片绿阴阴凉;
假如生命是一朵鲜花,我愿为世界奉上一缕馨香;
假如生命是一枚果实,我愿为人间留下一丝甘甜。
"""
obj = re.compile(r"假如生命是(?P<喻体>.*?),我愿为.*?[;|。]",re.S)
res = obj.finditer(txt)
for i in res:
print(i.group("喻体"))
Return result:
一株小草
一棵大树
一朵鲜花
一枚果实
The role of re.S: ignore the newline character \n, and treat everything as a long string.
import re
a = """sdfkhellolsdlfsdfiooefo:
877898989worldafdsf"""
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print ('b is ' , b)
print ('c is ' , c)
Return result:
b is []
c is ['lsdlfsdfiooefo:\n877898989']