An anonymous function is a function without a name. An anonymous function is created in Python using the lambda keyword.
However, what is the role of anonymous functions, or what is the application scenario?
In fact, lambda expressions are a concept in functional programming languages.
Lambda expressions are also used many times in TinyDB, and this article will introduce the use of lambda expressions in detail.
2 lambda functions
2.1 Definitions
Anonymous functions are supported in Python, but compared to ordinary functions, anonymous functions have many limitations. The specific limitations will be described below.
Python lambdas are little, anonymous functions, subject to a more restrictive but more concise syntax than regular Python functions.
An anonymous function is a function without a name. An anonymous function is created in Python using the lambda keyword.
Taken literally, an anonymous function is a function without a name. In Python, an anonymous function is created with the lambda keyword. More loosely, it may or not be assigned a name.
Note that the lambda syntax is just syntactic sugar, and like the def keyword, lambda expressions also create function objects.
Python's simple syntax restricts the body of a lambda function to pure expressions. In other words, you cannot assign values in lambda functions, and you cannot use Python statements such as while and try.
lambdas can be used to simplify the way functions are defined, but are mostly used for higher-order functions.
In fact, lambda expressions are a concept in functional programming languages.
2.2 Functional programming
Functional programming is a programming paradigm with a high degree of abstraction. The core idea of functional programming is stateless.
Functional programming requires that functions have input and output, and if the input is the same, the output is also the same, and will not change due to the difference in running state information.
Inside the function, you only need to care about defining the relationship between the input data and the output data. The mathematical expression is actually doing a kind of mapping.
The main features of functional programming include:
-
stateless, stateless, the data does not change during the process of processing the input data;
-
immutable, does not change the input data, each function returns a new data set.
The advantages mainly include:
-
No state, no harm
-
Parallel execution without harm
-
Copy-Paste refactoring code without harm
-
There is no order of execution of functions
Therefore, the code can be copied at will. Since there is no state, there is no mutual influence, and parallel execution does not require locks (locks that maintain state).
The disadvantage is that data replication is more serious, but due to the high degree of concurrency, it may actually improve performance, such as Erlang.
The techniques used in functional programming mainly include:
-
first class function, so functions can be created, modified like variables, passed and returned like variables, or functions can be nested within functions;
-
map & reduce, the most common technique of functional programming is to do Map and Reduce operations on a collection. If it is a traditional procedural language, you need to use for/while loops and create temporary variables, so functional programming is easier to read in code;
-
pipeline (pipeline), instantiate the function into actions one by one, then put a group of actions into an array or list, and then pass the data to the action list, the data is sequentially operated by each function like a pipeline , and finally get the result we want;
-
Recursing (recursion), the biggest advantage of recursion is to simplify the code, it can describe a complex problem with very simple code. Note: The essence of recursion is to describe the problem, which is the essence of functional programming;
-
currying (currying), decomposes multiple parameters of a function into multiple functions, and then encapsulates the function in multiple layers, and each layer of functions returns a function to receive the next parameter, which can simplify the multiple parameters of the function;
-
Higher order function (higher-order function), the so-called higher-order function is a function as a parameter, encapsulates the incoming function, and then returns the encapsulated function. The phenomenon is that functions are passed in and out, just like object-oriented flying all over the sky. This technique is great for decorators.
Here are two examples, one to illustrate the role of pure functions, and the other to illustrate the use of nested function calls in functional programming.
As shown below, the variable is not thread-safe because the function updates the global variable inside the function.
int cnt;void increment(){ cnt++;}
If it is changed to pure function, the code does not need to lock when parallel, because the original data is copied and new data is returned.
int increment(int cnt){ return cnt+1;}
In functional programming, a single function needs to be written in the form of a pure function, so what is the relationship between multiple functions?
Since functional programming functions have inputs and outputs, nested functions can be used directly.
The following is a data expression.
According to the traditional thinking of procedural programming, this may be achieved.
var a = 1 + 2;var b = a * 3;var c = b - 4;
According to the idea of functional programming, it will be implemented like this.
var result = subtract(multiply(add(1,2), 3), 4);
The reason is that functional programming requires that operations be written as a series of nested function calls as much as possible.
Therefore, the philosophy of functional programming is:
-
Use functions as variables and focus on describing the problem rather than how to implement it, which can make the code easier to read;
-
Because the function returns the function inside, the function focuses on the expression, and focuses on describing the problem, not how to implement it.
The idea of functional programming seems simple, but the excellent features that support parallel execution give program development unlimited imagination, and thus are widely used in distributed systems. For example, the two core components of the distributed platform Hadoop, distributed storage and distributed computing, are implemented based on HDFS and MapReduce respectively, and are used to develop and run applications that process massive data in a distributed system.
Among them, MapReduce is a parallel computing framework, which is essentially a programming model. The core idea is "divide and conquer". It is divided into three steps, including file splitting (split), parallel computing and result aggregation (merge). Thus, distributed parallel programming is abstracted into two primitive operations, namely map operation and reduce operation. Developers only need to simply implement the corresponding interface, without considering the details of the underlying data flow, fault tolerance, and parallel execution of programs.
Python is not a functional programming language (Functional Programming), but provides partial support for functional programming.
In 1994, map(), filter(), reduce() and lambda operators were introduced in Python.
Among them, lambda expressions have input and output, and only support expressions, which are typical applications of functional programming.
Next, we go back to lambda expressions and first introduce the syntax.
2.2 Syntax
2.2.1 Three elements
The syntax of a lambda expression is:
lambda arguments: expression
The following is an ordinary function identity(), which takes a parameter x and returns.
>>> def identity(x):... return x
Next, convert the normal function to an anonymous function.
As you can see, the three elements of anonymous functions include:
Note that the variable x belongs to the bound variable, which is different from the free variable in the closure. The former is the parameter passed to the lambda expression, and the latter is the variable in the outer function accessed by the inner function.
2.2.2 dis(lambda & def)
In fact, so far, it is difficult to see the relationship between lambda functions and ordinary functions, that is, similarities and differences.
Therefore, create anonymous functions and ordinary functions separately, and use the dis module to view the corresponding bytecodes.
The bytecode corresponding to the anonymous function is shown below.
>>> import dis>>> add_lambda = lambda x, y: x + y>>> type(add_lambda)<class 'function'>>>> dis.dis(add_lambda) 1 0 LOAD_FAST 0 (x) 2 LOAD_FAST 1 (y) 4 BINARY_ADD 6 RETURN_VALUE>>> add_lambda<function <lambda> at 0x00000201B792D0D0>
The bytecode corresponding to the normal function is shown below.
>>> def add_def(x, y): return x + y>>> type(add_def)<class 'function'>>>> dis.dis(add_def) 1 0 LOAD_FAST 0 (x) 2 LOAD_FAST 1 (y) 4 BINARY_ADD 6 RETURN_VALUE>>> add_def<function add_def at 0x00000201B7927E18>
It can be seen from the comparison that the bytecode corresponding to the anonymous function is exactly the same as that of the ordinary function. The function names of the two are different, and the function name of the anonymous function is unified as lambda.
Does this have any effect? For example, it will be difficult to locate the specific function when the anonymous function throws an exception.
As shown below, the anonymous function throws an exception and the function name printed in Traceback is lambda.
>>> div_zero = lambda x: x / 0>>> div_zero(2)Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 1, in <lambda>ZeroDivisionError: division by zero
Compared to the normal function throwing an exception, the function printed in Traceback is named div_zero.
>>> def div_zero(x): return x / 0>>> div_zero(2)Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 1, in div_zeroZeroDivisionError: division by zero
2.2.3 Syntax Features
Functions in Python are first-class objects, so they can be assigned to variables, as can anonymous functions.
As shown below, lambda expressions can be assigned to objects.
>>> add_one = lambda x: x + 1>>> add_one(2)3
Of course, anonymous functions can also be called directly if they are not assigned to objects, and parentheses are required around the expression. However, it is generally not recommended to call anonymous functions directly.
Another pattern used in other languages like JavaScript is to immediately execute a Python lambda function. This is known as an Immediately Invoked Function Expression (IIFE, pronounce “iffy”).
>>> (lambda x: x + 1)(2)3
The anonymous function above has one parameter, in fact it can also have no parameter or multiple parameters.
As shown below, there are no parameters in the anonymous function.
>>> hello = lambda : "hello world">>> hello()'hello world'
There are multiple parameters in an anonymous function, and parentheses are not used around multiple parameters.
>>> full_name = lambda first, last: f'Full name: {first.title()} {last.title()}'>>> full_name('guido', 'van rossum')'Full name: Guido Van Rossum'
2.2.4 Syntax Restrictions
The syntax limitations of anonymous functions mainly include:
-
Statements, such as assignment statements, are not supported;
-
Multiple expressions are not supported, only a single expression is supported;
-
Type annotations are not supported.
First, clarify the difference between the following statement and expression:
-
expression, expression, only supports identifiers, literals and operators, generates at least one value, so it can only be used as an rvalue;
-
Statement, a statement, usually composed of an expression, uses one or more lines of code to complete a specific function, such as an assignment statement, an if statement, and a return statement.
The following is an example of the use of statements and expressions.
>>> x + 2 >>> x = 1 >>> y = x + 1 >>> print(y) 2
As shown below, a syntax error is reported when the lambda expression contains a return statement and when the type annotation is used.
>>> (lambda x: return x)(2) File "<input>", line 1 (lambda x: return x)(2) ^SyntaxError: invalid syntax>>> >>> lambda x: int: x + 1 -> int File "<input>", line 1 lambda x: int: x + 1 -> int ^SyntaxError: invalid syntax
2.3 Use
Common uses include:
-
Assign an anonymous function to a variable, like a normal function call;
-
Nest the lambda into a normal function, and the lambda function itself is used as the value of return;
-
Pass lambda functions as parameters to other functions.
Among them, the function returning a function and passing a function to a function both satisfy the definition of a higher-order function.
In fact, Python rarely uses anonymous functions other than as arguments to higher-order functions. Lambda expressions are either hard to read or hard to write due to syntax limitations.
Higher-order functions are functions that take a function as an argument, or return a function as a result.
Lambda functions are frequently used with higher-order functions, which take one or more functions as arguments or return one or more functions.
2.3.1 Ordinary functions
Assigning an anonymous function to a variable is like a normal function call.
>>> f = lambda x, y, z: x * y * z>>> f(2, 3, 4)24
The corresponding ordinary function is shown below, which shows that it is not a higher-order function. The anonymous function here only serves to simplify the function definition.
def f(x, y, z): return x * y * z
2.3.2 Higher-order functions - function-returning functions
Nesting lambdas into ordinary functions, and the lambda function itself as the return value, is actually a currying (currying) technique.
The multiple parameters of a function are decomposed into multiple functions, and then the functions are encapsulated in multiple layers, and each layer of functions returns a function to receive the next parameter.
>>> def add(n):... return lambda x: x + n>>> f = add(1)>>> f(2)3
Note that the variable n in the outer function is referenced in the lambda function, thus satisfying the definition of the closure.
A closure is a function that binds free variables. You can use ordinary functions to implement closures, and you can also use lambda functions to implement closures.
The core feature of closures is to retain state between function calls.
The difference between a closure function and a nested function is that the outer function is required to return the inner function in the closure function.
In fact, Python's lambda expressions didn't support closures in the first place, so this feature didn't have a good reputation among functional programming geeks in the blogosphere. Python 2.2 (released in December 2001) fixes this problem, but the stereotype of the blogosphere won't change easily. Since then, with only syntactic differences, lambda expressions have been in an awkward position.
2.3.3 Higher-Order Functions - Function Receiving Functions
Passing a lambda function as a parameter to other functions, such as an anonymous function in a parameter list, works well.
As shown below, the higher-order function high_ord_func takes two parameters, one of which is that the parameter is a function.
def high_ord_func(x, func: Callable): return x + func(x)
It can be converted into a lambda function.
>>> high_ord_func = lambda x, func: x + func(x)>>> high_ord_func(2, lambda x: x * x)6>>> high_ord_func(2, lambda x: x + 3)7
However, this usage is still more deliberate, and the more common usage is to pass the lambda function to the filter function for even filtering.
>>> list(filter(lambda x: x % 2 == 0, [1, 2, 3, 4, 5, 6]))[2, 4, 6]
3 Applicable scenarios
Lambda functions are less readable and therefore often debated, but there are certain scenarios where lambda functions are appropriate.
mainly include:
-
Classic Functional Constructs, such as map(), filter(), functools.reduce();
-
Key Functions, such as sort(), sorted().
3.1 Classic Functional Constructs
Lambda functions are widely used in built-in functions such as map(), filter(), functools.reduce().
Lambda functions are regularly used with the built-in functions map() and filter(), as well as functools.reduce(), exposed in the module functools.
in:
-
map(function, iterable, ...), map the specified sequence according to the provided function;
-
filter(function, iterable), filter the specified sequence according to the provided function;
-
reduce(function, iterable[, initializer]), accumulate the adjacent elements in the specified sequence according to the provided function;
The same point of the three is that functions and iterable objects are passed into the function. The difference is that the types of output results are different. The input and output lengths of map are the same, the output length of filter is less than or equal to the input, and the output length of reduce can be considered to be equal to 1.
Note that for the map and filter functions, Python 2.x versions return lists, and Python 3.x versions return iterators.
>>> from collections import Iterable, Iterator>>> isinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterable)True>>> isinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterator)False
>>> from collections import Iterable, Iterator>>> isinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterable)True>>> isinstance(map(lambda x: x.upper(), ['cat', 'dog', 'cow']), Iterator)True
As shown below, the map, filter, and reduce functions are called respectively.
>>> list(map(lambda x: x.upper(), ['cat', 'dog', 'cow']))['CAT', 'DOG', 'COW']
>>> list(filter(lambda x: 'o' in x, ['cat', 'dog', 'cow']))['dog', 'cow']
>>> from functools import reduce>>> reduce(lambda acc, x: f'{acc} | {x}', ['cat', 'dog', 'cow'])'cat | dog | cow'
In fact, map, filter, reduce functions can often be converted into list comprehensions or generator expressions.
Higher-order functions like map(), filter(), and functools.reduce() can be converted to more elegant forms with slight twists of creativity, in particular with list comprehensions or generator expressions.
如下所示,将 map、filter 转换成列表推导式。
>>> [x.upper() for x in ['cat', 'dog', 'cow']]['CAT', 'DOG', 'COW']>>> [x for x in ['cat', 'dog', 'cow'] if 'o' in x]['dog', 'cow']
当 reduce 中的函数是 sum()、min()、max() 时,通常可以转换成生成器表达式。
Generator expressions are especially useful with functions like sum(), min(), and max() that reduce an iterable input to a single value.
>>> reduce(lambda x, y: x + y, [3, 1, 2])6>>> sum(x for x in [3, 1, 2])6
列表推导式与生成器表达式的主要区别如下表所示。
|
类型
|
列表推导式
|
生成器表达式
|
|
语法
|
[]
|
()
|
|
返回值类型
|
iterable
|
lazy iterator
|
|
内存使用
|
creates all elements right away
|
creates a single element based on request
|
备注:生成器包括生成器表达式与生成器函数,其中生成器函数是包含 yield 关键字的函数。
使用示例如下所示。
>>> square_list = [n** 2 for n in range(5)]>>> square_list[0, 1, 4, 9, 16]>>> square_generator = (n** 2 for n in range(5))>>> square_generator<generator object <genexpr> at 0x00000286B8671F90>
3.2 Key Functions
Python 中的 Key Functions 指的是接收命名参数 key 的高阶函数,Key Functions 可以是 lambda 函数。
Key functions in Python are higher-order functions that take a parameter key as a named argument. key receives a function that can be a lambda.
常见的 Key Functions 如 sort()、sorted() 。
其中:
-
sort(key, reverse),根据提供的函数对调用列表做排序;
-
sorted(iterable[, key[, reverse]]),根据提供的函数对指定序列做排序。
两个函数的参数都是 key 与 reverse,其中:
注意 sort 是 list 的一个方法,用于进行原地排序,sorted 可以对所有可迭代对象排序,并返回新的可迭代对象。
如下所示,分别使用 sort 与 sorted 函数对 ss 序列根据 age 字段进行排序。
>>> ss = [(10, "Tom", ), (8, "Jack"), (5, "David")]>>> ss.sort(key=lambda x: x[1])>>> ss[(5, 'David'), (8, 'Jack'), (10, 'Tom')]>>> sorted(ss, key=lambda x: x[1], reverse=True)[(10, 'Tom'), (8, 'Jack'), (5, 'David')]
4 TinyDB
TinyDB 的 Query 模块用于处理查询条件,其中多次使用 lambda 函数。
在具体介绍 lambda 语句之前,首先介绍下查询流程,便于理解使用 lambda 表达式的作用。
4.1 查询流程
数据查询有两个变量,包括表中的数据与查询条件,然后判断数据是否满足查询条件。
search(cond) 方法中遍历指定表的全部记录,依次执行 cond(doc) 函数进行条件过滤。
cond(doc) 函数中 cond 对应查询条件,doc 对应数据。
因此,可以将执行流程分为三步:
以如下查询语句为例。
>>> table.search(User.name == 'shawn')
具体实现是将一条语句的执行拆分为多次函数调用,完整的查询操作对应的流程图如下所示。
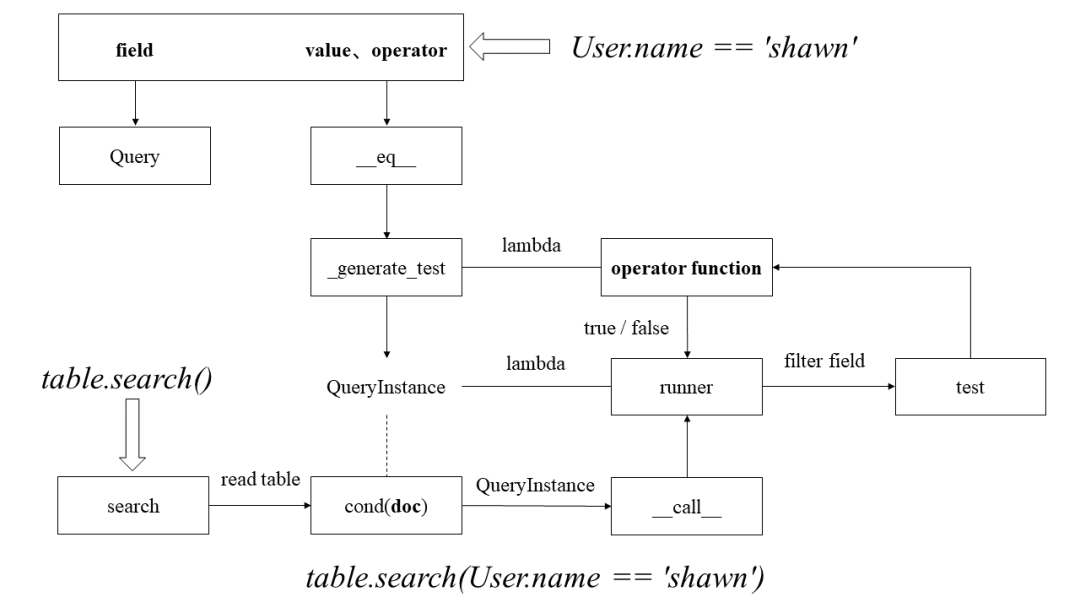
函数调用包括:
-
将查询条件 User.name == 'shawn' 转换成查询函数 lambda value: value == 'shawn',并将其保存在 QueryInstance 对象中。注意现在还并不知道具体表的数据;
-
获取要查询的数据表,然后调用 cond(doc) 方法判断是否满足查询条件;
-
由于 QueryInstance 类实现了 __call__() 方法,因此实际是传入表中数据并调用查询函数 lambda value: value == 'shawn'(doc.name)。
因此,TinyDB 的 Query 模块中将查询函数的多个参数分解成多个函数,每层函数都返回一个函数去接收下一个参数,正是 currying(柯里化)技术的应用。比如一个参数接收查询条件,一个参数用于接收表中数据。要将参数分解的原因是将执行过程拆解,按照顺序传入参数。
下面分别介绍其中的 __eq__() 与 _generate_test() 方法。
4.2 实现
4.2.1 __eq__
__eq__() 方法中调用 _generate_test() 方法并返回,其中声明匿名函数进行等值判断。
而 _generate_test() 是高阶函数,其中接收函数作为参数。
class Query(QueryInstance): def __eq__(self, rhs: Any): return self._generate_test( lambda value: value == rhs, ('==', self._path, freeze(rhs)) )
如下所示,高阶函数 _generate_test 参数中的匿名函数 lambda value: value == rhs 可以使用普通函数即 __eq__() 方法中的嵌套函数替代。
def __eq__(self, rhs: Any): def temp(value): return value == rhs
return self._generate_test( temp, ('==', self._path, freeze(rhs)) )
嵌套函数的核心特性是内部函数可以在外部函数返回后访问到外部函数中的局部变量,因此 lambda 函数可以访问到 __eq__() 方法中的局部变量 rhs。当外部传入 value 后,就可以判断指定记录是否满足查询条件了。
4.2.2 _generate_test
_generate_test() 方法中输入查询函数,返回 QueryInstance 对象,其中声明一个匿名函数用于调用嵌套函数 runner()。
而 runner() 函数中最终调用传入的 test() 函数进行条件判断。
def _generate_test( self, test: Callable[[Any], bool], hashval: Tuple, allow_empty_path: bool = False) -> QueryInstance: def runner(value): ... return test(value)
return QueryInstance( lambda value: runner(value), (hashval if self.is_cacheable() else None) )
5 结论
匿名函数是没有名字的函数,Python 中使用 lambda 关键字创建匿名函数。
lambda 表达式是函数式编程语言中的概念。
普通的匿名函数仅起到简化函数定义的作用,因此 Python 中匿名函数主要用于作为参数传给高阶函数。
实际上,由于语法限制,lambda 表达式要么难以阅读,要么难以写出。
高阶函数(higher-order functions)是接收函数作为参数,或者把函数作为结果返回的函数。
匿名函数的使用示例如:
TinyDB 的 Query 模块用于处理查询条件,其中多次使用 lambda 函数。
将数据查询操作抽象成 cond(doc) 函数,其中包括两个变量,cond 对应查询条件,doc 对应数据。
通过将查询函数的多个参数分解成多个函数,每层函数都返回一个函数去接收下一个参数,正是 currying(柯里化)技术的应用。比如一个参数接收查询条件,一个参数用于接收表中数据。要将参数分解的原因是将执行过程拆解,按照顺序传入参数。
6 待办
7 小技巧
7.1 函数式编程
函数式编程是一种抽象程度很高的编程范式,函数式编程的核心思想是 stateless。
函数式编程要求函数有输入有输出,而且如果输入相同时,输出也相同,不会因为运行中的状态信息的不同而发生变化。
函数内部只需要关心定义输入数据和输出数据之间的关系,数学表达式里面其实是在做一种映射(mapping)。
函数式编程的思想看起来很简单,但是支持并行执行的优秀特性给了程序开发无限的想象力,并因此被广泛应用于分布式系统。比如分布式平台 Hadoop 中的并行计算框架 MapReduce,本质上一种编程模型,核心思想是“分而治之”。具体分为三步,包括文件切分(split)、并行计算与结果汇总(merge)。
注意函数式编程是一种编程思想,比如将一个函数的多个参数分解成多个函数(currying), 然后将函数多层封装起来,每层函数都返回一个函数去接收下一个参数,这可以简化函数的多个参数。
比如之前介绍嵌套函数的使用时举例 generate_power() 函数,实际上就是 currying 技术的应用,
def generate_power(exponent): def power(base): return base ** exponent return power
generate_power() 函数返回 power() 函数,因此可以用 generate_power() 函数构造各种版本的 generate_power 函数,根据闭包机制其中可以保存对应的自由变量。
当然,也可以将嵌套函数中的 power() 函数转换成匿名函数。
def generate_power_lambda(exponent): return lambda base: base ** exponent
7.2 map 在线程池中的应用
Python 中线程池 concurrent.futures.ThreadPoolExecutor 获取执行结果的方式有三种,包括 直接调用 result()、调用 as_completed()、调用 map()。
其中 map 方法与 Python 标准库中的 map 含义相同,都是给可迭代对象中的每个元素都执行同一个函数。
map 方法与 as_completed 方法的相同点在于返回值都是一个迭代器。
区别主要有以下三点:
-
map 方法中自动调用 submit 方法,因此无需提前使用 submit 方法;
-
map 方法中自动调用 result 方法,返回值是 result 的迭代器,而 as_completed 方法的返回值是 Future 实例对象的迭代器;
-
map 方法中任务返回的顺序与任务提交的顺序一致,而 as_completed 方法中任务返回的顺序与任务提交的顺序可能不一致。
三种方式的使用示例分别如下所示。
直接调用 result() 时主线程阻塞直到任务执行结束。
from concurrent.futures import ThreadPoolExecutorfrom my_thread.tasks import get_html
def main(): executor = ThreadPoolExecutor(max_workers=2) task1 = executor.submit(get_html, 3) task2 = executor.submit(get_html, 2) task3 = executor.submit(get_html, 2) print(task1.result()) print(task2.result()) print(task3.result())
调用 as_completed() 方法返回一个 Future 实例对象的迭代器,可以一次取出所有任务的结果。
from concurrent.futures import as_completed
def main(): pool = ThreadPoolExecutor(max_workers=2) urls = [3, 2, 4] all_task = [pool.submit(get_html, url) for url in urls]
for future in as_completed(all_task): data = future.result() print("in main thread, result={}".format(data))
调用 map() 时,自动调用 submit() 与 result() 方法,因此代码是最简洁的。
def main(): pool = ThreadPoolExecutor(max_workers=2) urls = [3, 2, 4] for result in pool.map(get_html, urls): print(result)
可见通过 map() 方法可以简化并行代码的实现。
实际上 map() 方法中显式调用 submit() 方法,并调用 result() 方法异步返回执行结果。
def map(self, fn, *iterables, timeout=None, chunksize=1): """Returns an iterator equivalent to map(fn, iter). """
fs = [self.submit(fn, *args) for args in zip(*iterables)]
def result_iterator(): try: fs.reverse() while fs: if timeout is None: yield fs.pop().result() else: yield fs.pop().result(end_time - time.time()) finally: for future in fs: future.cancel() return result_iterator()
参考教程
https://realpython.com/python-lambda/#alternatives-to-lambdas
https://www.machinelearningplus.com/python/lambda-function/#3.-What-is-the-need-for-Lambda-Functions-in-Python?
https://time.geekbang.org/column/article/2711
https://www.ruanyifeng.com/blog/2012/04/functional_programming.html
https://blog.csdn.net/qq_40089648/article/details/89022804
https://blog.csdn.net/PY0312/article/details/88956795