eBPF ( Extended Berkeley Packet Filter ) originated in the Linux kernel and is a sandboxed program that can run in the operating system kernel. Its technology safely and efficiently extends the kernel functionality. Without changing the kernel source code or loading kernel modules.
eBPF is widely used for:
-
Kernel performance trace
-
Cybersecurity and Observability
-
Application and container runtime security
...
1. The general process of eBPF program execution
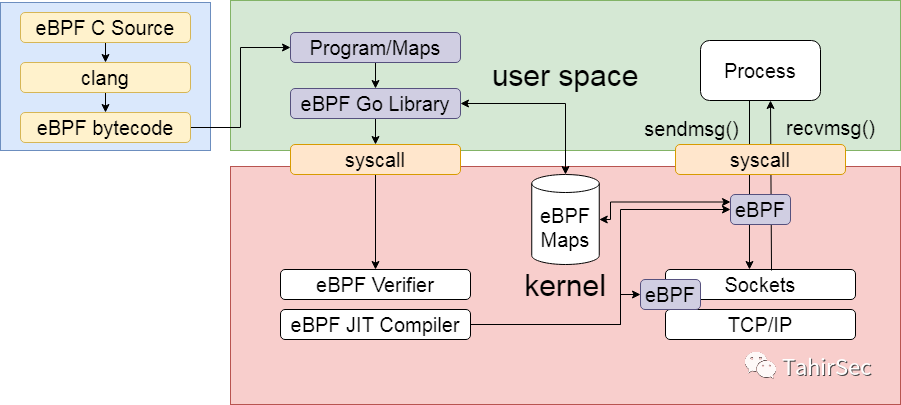
The eBPF program first uses C or Rust to write the eBPF program, LLVM compiles it into bytecode, and the user-mode program uses the eBPF library to load the eBPF bytecode into the Linux kernel using the bpf system call.
Kernel ebpf validator, verifying BPF bytecode:
-
Whether the process that initiates the bpf system call has the corresponding permissions, the process is required to have the relevant Linux Capabilities (CAP_BPF) or root permissions;
-
Check whether the program will cause the kernel to crash, such as whether there are uninitialized variables, whether there are statements that may cause array out-of-bounds, null pointer access;
-
Check whether the program is executed in a limited time, eBPF only allows limited loops and jumps, and only allows a limited number of instructions to be executed.
After the eBPF program is built, it is mounted on the corresponding event on the kernel, such as a system call. When a system call is generated, the kernel is triggered to call the corresponding eBPF program. The kernel ebpf program interacts with the user-mode program through the map data structure to complete the corresponding functions.
2. eBPF Tracking
2.1 Types of probes
Kernel probes: provide dynamic access to internal components in the kernel
Tracepoints: Provides dynamic access to programs running in user space
Userspace probes: Provides dynamic access to programs running in userspace
User statically defined tracepoints: Provides static access to programs running in user space
2.2 Kernel probe
Kernel probes can set dynamic flags or interrupts on any kernel instruction, and when the kernel reaches these flags, the code attached to the probe will be executed, after which the kernel will resume normal mode.
Kernel probes are divided into two categories: kprobes and kretprobes.
2.2.1 kprobes
kprobes allow to insert BPF programs before executing any kernel instructions, need to know the function signature of the insertion point, kernel probes are not stable ABI (Program Binary Interface), so one needs to be careful to run programs that set probes in different kernel versions . When the kernel executes the instruction to set the probe, it will start running the BPF program from the point of code execution, and will return to the place where the BPF program was inserted to continue execution after the execution of the BPF program is completed.
2.2.2 kretprobes
kretprobes are inserted into the BPF program when the kernel instruction has a return value. Often, we use both kprobes and kretprobes in a BPF program in order to gain a comprehensive understanding of kernel instructions.
2.3 Tracking Points
Tracepoints are static markers of kernel code that can be used to attach code to a running kernel. The main difference between tracepoints and kprobes is that tracepoints are written and modified in the kernel by the kernel developers. Since the trackpoint exists statically, the ABI of the tracker is the most stable.
Tracepoints are added by the kernel developers, so tracepoints may not cover all subsystems of the kernel.
The contents of the /sys/kernel/debug/tracing/events directory can view all available trace points in the system.
Each subdirectory in the above output corresponds to a tracepoint to which a BPF program can attach. There are two additional files: the first file is enable, which allows to enable and disable all tracepoints of the BPF subsystem. If the content of this file is 0, it means that the tracepoint is disabled. If the file content is 1, the tracepoint is enabled.
Kernel probes and tracepoints provide full access to the kernel. Use trace points whenever possible because they are more secure.
2.4 User space probe
Userspace probes allow dynamic flags to be set in programs running in userspace. They are equivalent to kernel probes, and user space probes are monitoring systems running in user space. When we define the probe, the kernel will create a trap on the attached instruction, and when the program executes the instruction, the kernel will trigger the event to call the probe function by calling the callback function. Uprobes can also access any library that the program is linked to, and as long as the name of the instruction is known, the corresponding call can be traced.
Much like kernel probes, userspace probes also fall into two categories: uprobes and uretporbes, depending on which phase of the instruction cycle the inserted BPF program is in.
2.4.1 Uprobes
Uprobes are hooks that the kernel inserts into a program-specific instruction set before it executes. Function signatures may vary for different kernel versions. In Linux, you can use the nm command to list all the symbols included in the ELF object file and check whether the trace instruction exists in the program.
2.4.2 uretprobes
uretprobes are kretprobes parallel probes, suitable for use by user-space programs. It appends the BPF program to the instruction return value, allowing the return value to be accessed from registers through BPF code.
The combination of uprobes and uretprobes can write more complex BPF programs.
● eBPF allows the creation of in-kernel tracepoints at
○ System calls
○ Network interface (socket/xdp)
○ Function entry/exit
○ Kernel tracepoints
○ Containers (cgroups)
○ User mode function
...
● eBPF allows to create probes:
○ Kernel probe (kprobe)
○ User probe (uprobe)
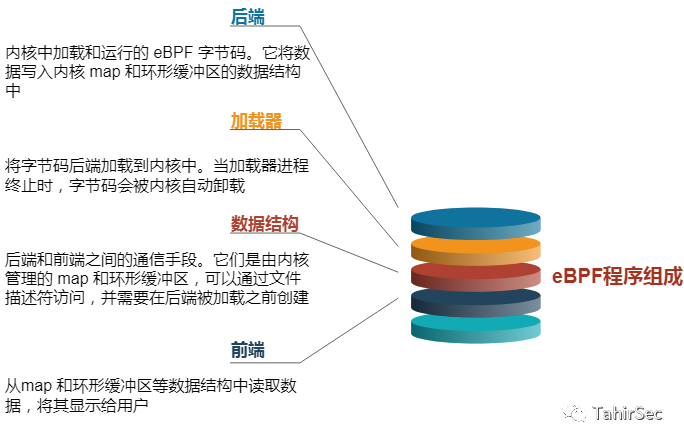
3. eBPF program components
4. eBPF mapping
BPF maps are stored in the kernel as key/values and can be accessed by any BPF program. Userspace programs can also access BPF maps through file descriptors. Any type of data that implements a specified size can be stored in a BPF map. The kernel treats keys and values as binary blocks, which means the kernel doesn't care what exactly the BPF map holds.
BPF validators use several safeguards to ensure that BPF maps are created and accessed in a secure manner.
The most straightforward way to create a BPF map is to use the bpf system call. If the first parameter of this system call is set to BPF_MAP_CREATE, it means to create a new map. This call will return the file descriptor associated with creating the map. The second parameter of the bpf system call is the setting for the BPF map.
union bpf_attr(){struct {__u32 map_type; /*bpf_map_type*/__u32 key_size;__u32 value_size;__u32 max_entries;__u32 map_flags;};}
The third argument to the bpf system call is to set the size of the property, creating a hash table mapping of keys and unsigned integers:
union bpf_attr_my_map {.map_type = BPF_MAP_TYPE_HASH,.key_size = sizeof(int),.value_size = sizeof(int),.max_entries = 100,.map_flags = BPF_F_NO_PREALLOC,};int fd = bpf(BPF_MAP_CREATE, &my_map, sizeof(my_map));
If the system call fails, the kernel returns -1. There are three reasons for the failure, which are distinguished by errno.
-
If the attribute is invalid, the kernel returns EINVAL.
-
If there are insufficient privileges to perform the operation, the kernel returns EPERM.
-
If there is not enough memory to hold the mapping, the kernel will return ENOMEM.
4.1 Creating BPF Maps Using ELF Conventions
Some conventions and helper functions exist in the kernel for generating and using BPF maps. Even though these conventions are running in the kernel, the bottom layer is still through the bpf system call to create the mapping.
The helper function bpf_map_create encapsulates the code we used above and can easily initialize the map on demand.
int fd;fd = bpf_map_create(BPF_MAP_TYPE_HASH, sizeof(int), sizeof(int), 100, BPF_F_NO_PREALOC);
4.2 Using BPF Mapping
Communication between the kernel and user space is the basis for writing BPF programs. Both kernel and user-space program code can access the map, but they use different API signatures.
4.2.1 Updating BPF Map Elements
Create map update content, the kernel provides a helper function bpf_map_update_elem to achieve.
The kernel program needs to load the bpf_map_update_elem function from the bpf/bpf_helpers.h file, and the user program needs to load from the tools/lib/bpf/bpf.h file, so the function signature accessed by the kernel program is different from the function signature accessed by the user space.
The kernel program can directly access the map, while the user program needs to use the file descriptor to refer to the map.
int key, value, result;key = 1, value = 1234;result = bpf_map_update_elem(map_data[0].fd, &key, &value, BPF_ANY);if(result == 0)printf("Map updated with new element\n");elseprintf("Failed to update map with new value: %d (%s)\n", result, strerror(errno));
4.2.2 Reading BPF Map Elements
BPF provides two different helper functions for reading map elements depending on where the program is executing. Both function names are bpf_map_lookup_elem.
Read the map from kernel space:
int key, value, result;key = 1;result = bpf_map_lookup_elem(&my_map, &key, &value);if(result == 0)printf("Value to read from the map: '%d'\n", value);elseprintf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));
Read the map from user space:
int key, value, result;key = 1;result = bpf_map_lookup_elem(map_data[0].fd, &key, &value);if(result == 0)printf("Value to read from the map: '%d'\n", value);elseprintf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));
The first parameter in bpf_map_lookup_elem will be replaced with the mapped file descriptor. The helper function behaves the same as the example above.
4.2.3 Deleting BPF Map Elements
BPF provides two different helper functions to delete map elements depending on where the program is executed. Both function names are bpf_map_delete_element.
Delete the value inserted in the map from kernel space:
int key, value, result;key = 1;result = bpf_map_delete_element(&my_map, &key);if(result == 0)printf("Element deleted from the map\n");elseprintf("Failed to delete element from the map: %d (%s)\n", result, strerror(errno));
Read the map from user space:
int key, value, result;key = 1;result = bpf_map_delete_element(map_data[0].fd, &key);if(result == 0)printf("Element deleted from the map\n");elseprintf("Failed to delete element from the map: %d (%s)\n", result, strerror(errno));
4.2.4 Iterating over BPF map elements
Find any element in BPF. BPF provides the bpf_map_get_next_key instruction, which only applies to programs running in user space.
int next_key, lookup_key;lookup_key = -1;while(bpf_map_get_next_key(map_data[0].fd, &lookup_key, &next_key) == 0){printf("The next key in the map is: '%d'\n", next_key);lookup_key = next_key;}
4.2.5 Finding and Deleting Map Elements
bpf_map_lookup_and_delete_elem. This function is to find the specified key in the map and delete the element. At the same time, the program assigns the value of the element to a variable.
int key, value, result, it;key = 1;for (it =0; it < 2; it++){result = bpf_map_lookup_and_delete_element(map_data[0].fd, &key, &value);if(result == 0)printf("Value read from the map: '%d'\n", value);elseprintf("Failed to read value from the map: %d (%s)\n", result, strerror(errno));}
4.2.6 Concurrent access to map elements
Accessing the same map elements concurrently can create race conditions in BPF programs. BPF adds the concept of BPF spin lock, which can lock the accessed map elements when operating map elements. Spinlocks are only available for arrays, hashes, and cgroup storage maps.
There are two helper functions in the kernel for use with spinlocks: bpf_spin_lock lock, bpf_spin_unlock unlock. User programs can use the BPF_F_LOCK flag.
Using a spinlock first requires creating the element you want to lock access to, then adding a signal to that element.
struct concurrent_element{struct bpf_spin_lock semaphore;int count;}
We can declare a map that holds these elements. The mapping must be annotated with the BPF Type Format (BTF) so that the validator knows how to interpret the BTF. BTF can provide richer information to the kernel and other tools by adding debug information to binary objects. In the kernel, we can use libbpf's kernel macros to annotate this concurrent map.
struct bpf_map_def SEC("maps") concurrent_map = {.type = BPF_MAP_TYPE_HASH,.key_size = sizeof(int),.value_size = sizeof(struct concurrent_element),.max_entries = 100,};BPF_ANNOTATE_KV_PAIR(concurrent_map, int, struct concurrent_element);
Use these two helper functions to protect these elements from race conditions.
5. BPF Mapping Types
5.1 Hash table mapping
Hash table mappings are the first general purpose mappings added to BPF. The map type is defined as BPF_MAP_TYPE_HASH.
5.2 Array mapping
The array map is the second BPF map added to the kernel. The map type is defined as BPF_MAP_TYPE_ARRAY. When an array map is initialized, all elements are pre-allocated in memory and set to zero. The key is the index into the array and must be exactly four bytes in size. Elements in an array map cannot be deleted.
5.3 Program Array Mapping
The program array map is added to the first dedicated map of the kernel. The map type is defined as BPF_MAP_TYPE_PROC_ARRAY. This type holds a reference to the BPF program, the file descriptor of the BPF program. The program array mapping type can be used in conjunction with the helper function bpf_tail_call to jump between programs, break through the limit of the maximum instruction of a single BPF program, and reduce the complexity of the implementation. The key and value must be four bytes in size. When jumping to a new program, the new program will use the same memory stack, so the program will not use up all available memory. If you jump to a non-existing program, the tail call will fail and return to continue executing the current program.
5.4 Perf event array mapping
This typemap stores perf_events data in a ring buffer for real-time communication between BPF programs and userspace programs.
The map type is defined as BPF_MAP_TYPE_PERF_EVENT_ARRAY. It can forward events emitted by kernel tracing tools to user-space programs for further processing.
Declare the event structure:
struct data_t{u32 pid;char program_name[16];}
Create a mapping to send events to user space:
struct bpf_map_def SEC("maps") events = {.type = BPF_MAP_TYPE_PERF_EVENT_ARRAY,.key_size = sizeof(int),.value_size = sizeof(u32),.max_entries = 2,}
After declaring the data type and mapping, we can create a BPF program to capture the data and send it to user space:
SEC("kprobe/sys_exec")int bpf_capture_exec(struct pt_regs *ctx){data_t data;data.pid = bpf_get_current_pid_tgid() >> 32;bpf_get_current_comm(&data.program_name, sizeof(data.program_name));bpf_perf_event_output(ctx, &events, 0, &data, sizeof(data));return 0;}
reference
"Linux Kernel Observation Technology BPF"
https://ebpf.io/zh-cn/