Pay attention, do not get lost in dry goods👆
Introduction
This article mainly learns and understands the characteristics of map by exploring the data structure and source code implementation of map in golang, including model exploration, access, and expansion of map. Welcome to discuss together.
Map's underlying memory model
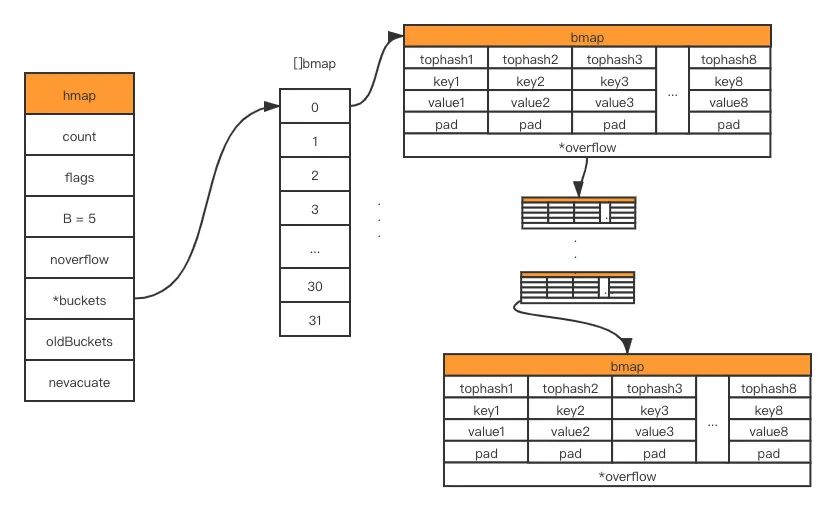
In the source code of golang, the underlying struct representing map is hmap, which is the abbreviation of hashmap
type hmap struct {
// map中存入元素的个数, golang中调用len(map)的时候直接返回该字段
count int
// 状态标记位,通过与定义的枚举值进行&操作可以判断当前是否处于这种状态
flags uint8
B uint8 // 2^B 表示bucket的数量, B 表示取hash后多少位来做bucket的分组
noverflow uint16 // overflow bucket 的数量的近似数
hash0 uint32 // hash seed (hash 种子) 一般是一个素数
buckets unsafe.Pointer // 共有2^B个 bucket ,但是如果没有元素存入,这个字段可能为nil
oldbuckets unsafe.Pointer // 在扩容期间,将旧的bucket数组放在这里, 新buckets会是这个的两倍大
nevacuate uintptr // 表示已经完成扩容迁移的bucket的指针, 地址小于当前指针的bucket已经迁移完成
extra *mapextra // optional fields
}
B is the logarithm of the length of the buckets array, that is, the length of the bucket array is 2^B. The bucket is essentially a pointer that points to a memory space, and the struct it points to is as follows:
// A bucket for a Go map.
type bmap struct {
tophash [bucketCnt]uint8
}
But this is just the structure of the surface (src/runtime/hashmap.go), which is fed during compilation, creating a new structure dynamically:
type bmap struct {
topbits [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr // 内存对齐使用,可能不需要
overflow uintptr // 当bucket 的8个key 存满了之后
}
bmap is the underlying data structure of what we often call "buckets". A bucket can store up to 8 keys/values. Map uses the hash function to get the hash value to decide which bucket to allocate to, and then according to the upper 8 bits of the hash value Find where to put it in the bucket The
composition of the specific map is shown in the following figure:
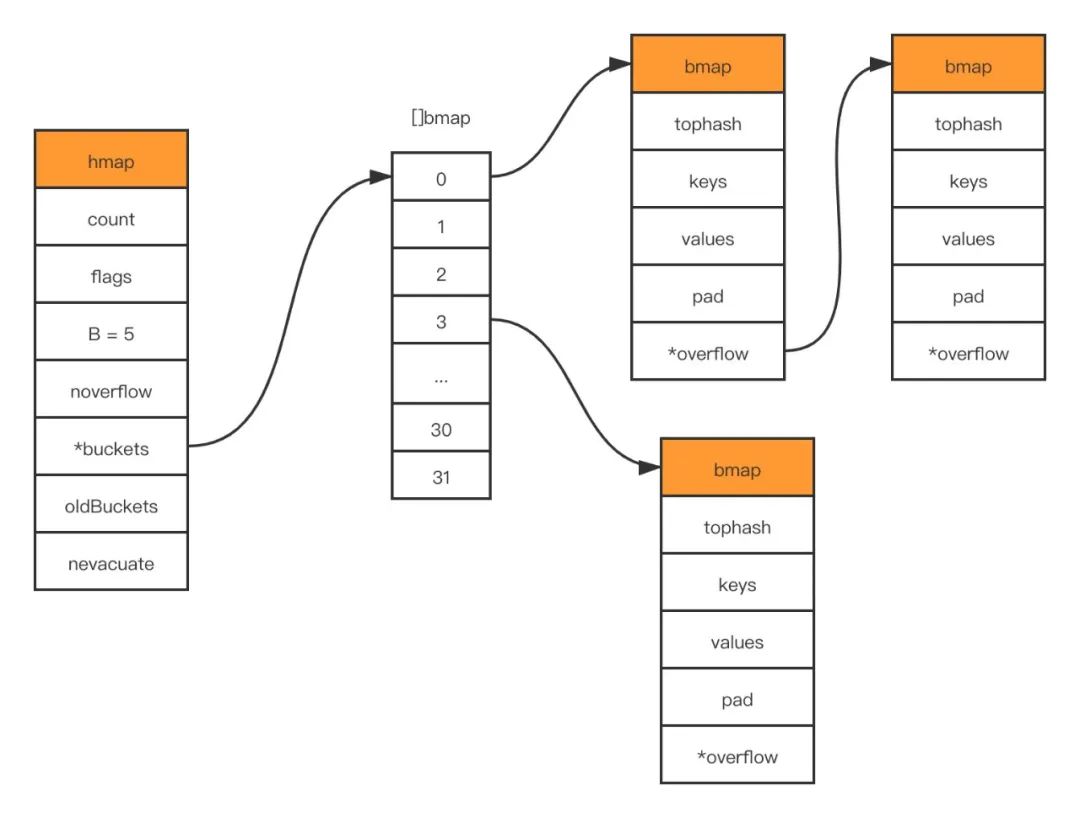
Map storage and retrieval
In the map, the storage and retrieval are essentially doing a job, that is:
-
Query where the current k/v should be stored. -
Assignment/value, so we understand the positioning of the key in the map and we understand the access.
low-level code
func mapaccess2(t *maptype, h *hmap, key unsafe.Pointer) (unsafe.Pointer, bool) {
// map 为空,或者元素数为 0,直接返回未找到
if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0]), false
}
// 不支持并发读写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}
// 根据hash 函数算出hash值,注意key的类型不同可能使用的hash函数也不同
hash := t.hasher(key, uintptr(h.hash0))
// 如果 B = 5,那么结果用二进制表示就是 11111 , 返回的是B位全1的值
m := bucketMask(h.B)
// 根据hash的后B位,定位在bucket数组中的位置
b := (*bmap)(unsafe.Pointer(uintptr(h.buckets) + (hash&m)*uintptr(t.bucketsize)))
// 当 h.oldbuckets 非空时,说明 map 发生了扩容
// 这时候,新的 buckets 里可能还没有老的内容
// 所以一定要在老的里面找,否则有可能发生“消失”的诡异现象
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
// 说明之前只有一半的 bucket,需要除 2
m >>= 1
}
oldb := (*bmap)(unsafe.Pointer(uintptr(c) + (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) {
b = oldb
}
}
// tophash 取其高 8bit 的值
top := tophash(hash)
// 一个 bucket 在存储满 8 个元素后,就再也放不下了,这时候会创建新的 bucket,挂在原来的 bucket 的 overflow 指针成员上
// 遍历当前bucket的所有链式bucket
for ; b != nil; b = b.overflow(t) {
// 在bucket的8个位置上查询
for i := uintptr(0); i < bucketCnt; i++ {
// 如果找到了相等的 tophash,那说明就是这个 bucket 了
if b.tophash[i] != top {
continue
}
// 根据内存结构定位key的位置
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey {
k = *((*unsafe.Pointer)(k))
}
// 校验找到的key是否匹配
if t.key.equal(key, k) {
// 定位v的位置
v := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.valuesize))
if t.indirectvalue {
v = *((*unsafe.Pointer)(v))
}
return v, true
}
}
}
// 所有 bucket 都没有找到,返回零值和 false
return unsafe.Pointer(&zeroVal[0]), false
}
addressing process
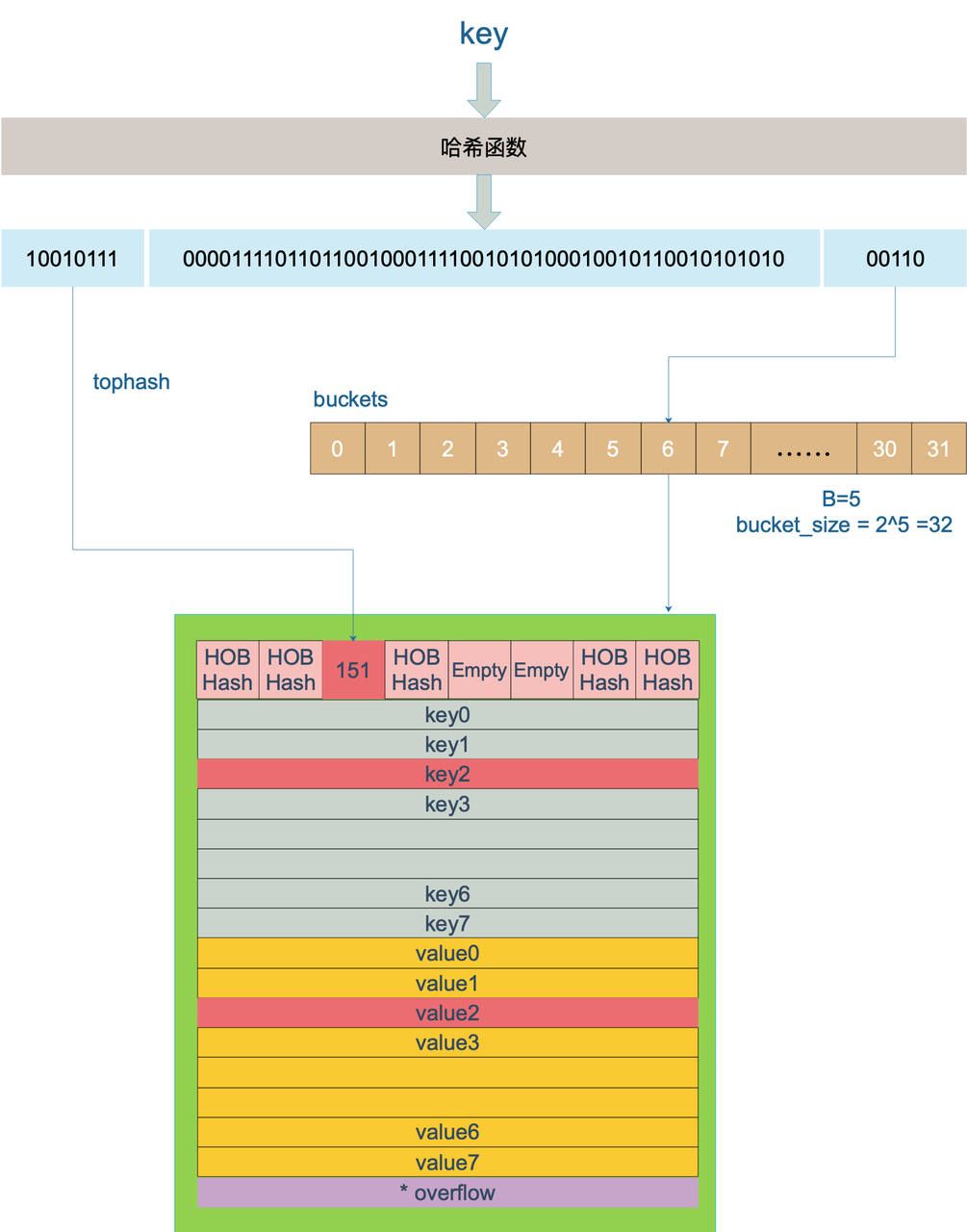
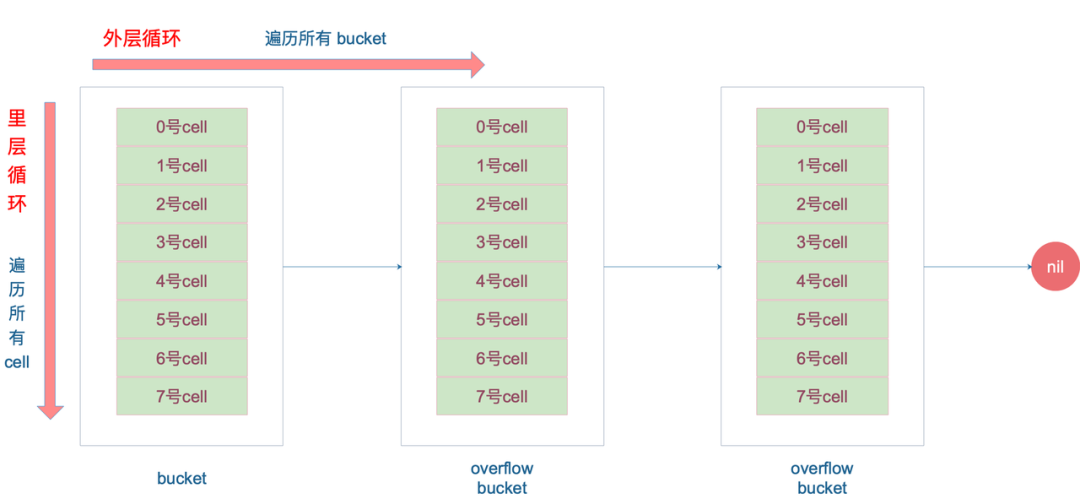
Expansion of Map
In golang, map and slice first apply for a small memory space during initialization, and dynamically expand the capacity in the process of continuous storage of map. There are two types of expansion, incremental expansion and equal expansion (rearrange and allocate memory). Let's take a look at how the expansion is triggered:
-
The load factor exceeds the threshold, and the threshold defined in the source code is 6.5. (Trigger incremental expansion) -
Too many overflow buckets: when B is less than 15, that is, the total number of buckets 2^B is less than 2^15, if the number of overflow buckets exceeds 2^B; when B >= 15, that is, the total number of buckets 2^B is greater than or equal to 2^15, if the overflow bucket number exceeds 2^15. (trigger equal expansion)
first case
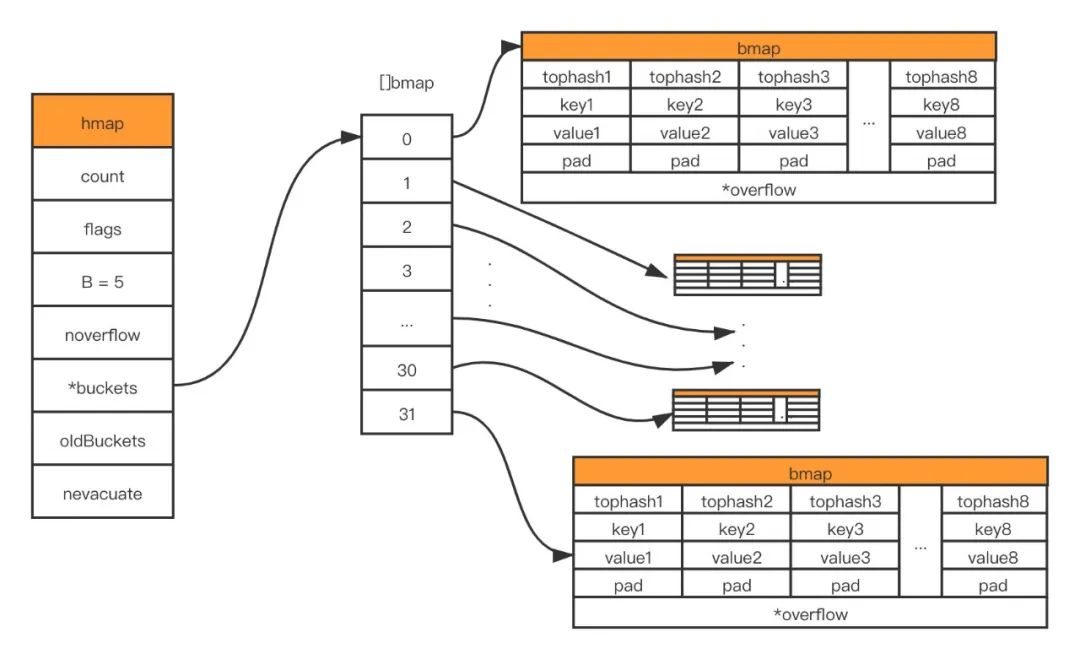
second case
Ordering of Maps
objMap := make(map[string]int)
for i := 0; i < 5; i++ {
objMap[strconv.Itoa(i)] = i
}
for i := 0 ; i < 5; i ++ {
var valStr1, valStr2 string
for k, v := range objMap {
fmt.Println(k)
fmt.Println(v)
valStr1 += k
}
for k, v := range objMap {
fmt.Println(k)
fmt.Println(v)
valStr2 += k
}
fmt.Println(valStr1 == valStr2)
if valStr1 != valStr2 {
fmt.Println("not equal")
}
}
fmt.Println("end")

-
Typical usage scenario: A typical usage scenario for map is that safe access from multiple goroutines is not required. -
Atypical scenarios (requires atomic operations): The map may be part of some larger data structure or an already synchronized computation.
, // 不支持并发读写
if h.flags&hashWriting != 0 {
throw("concurrent map read and map write")
}