Article: Python Crawler and Data Mining
Article: Python Crawler and Data Mining
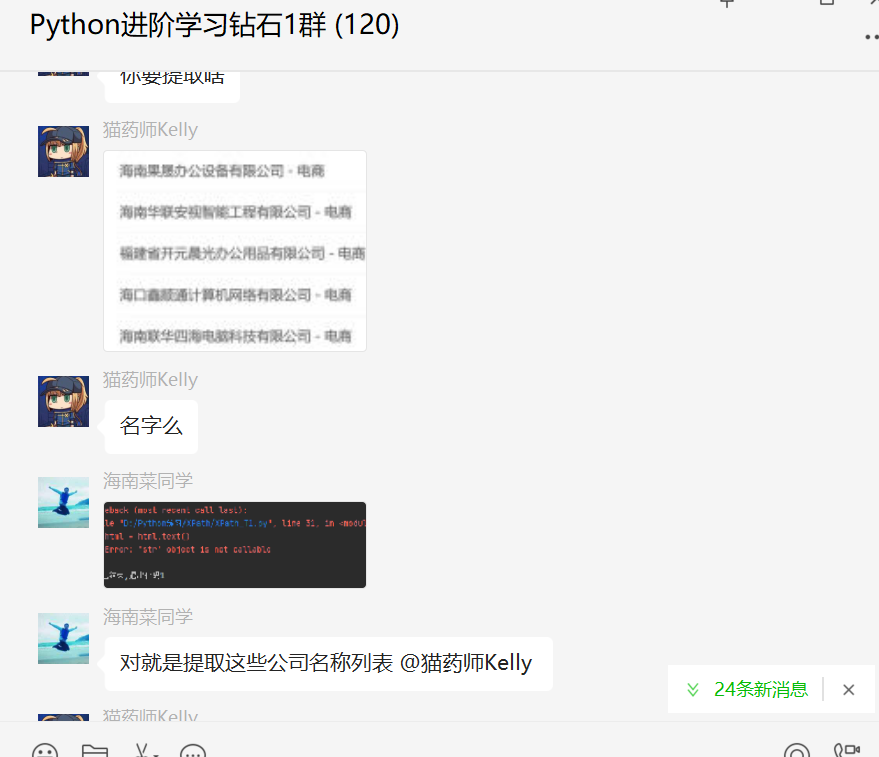
A few days ago, I asked a Python web crawler selector extraction question in the Python diamond exchange group [Hainan cuisine classmates]. The following picture is a screenshot:
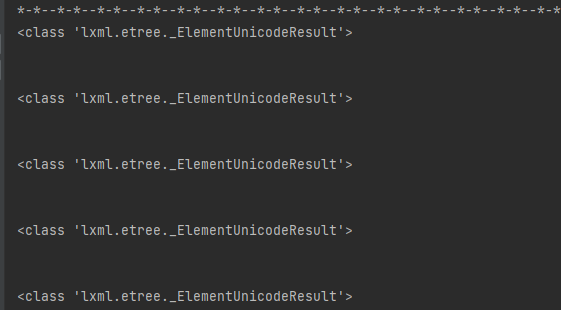
At first glance, the code seems to be fine, but it turns out that it is not right.
from lxml import etreeimport requestsurl = "http://zw.hainan.gov.cn/wssc/emalls.html"headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}html = requests.get(url,headers=headers)html = html.content.decode('utf-8')doc = etree.HTML(html)res = doc.xpath('/html/body/div[5]/ul/text()')print('*-*--'*20)for item in res: print(type(item)) print(item[0])
print('*-*--'*20)
The initial judgment is that there is a problem with the xpath written.
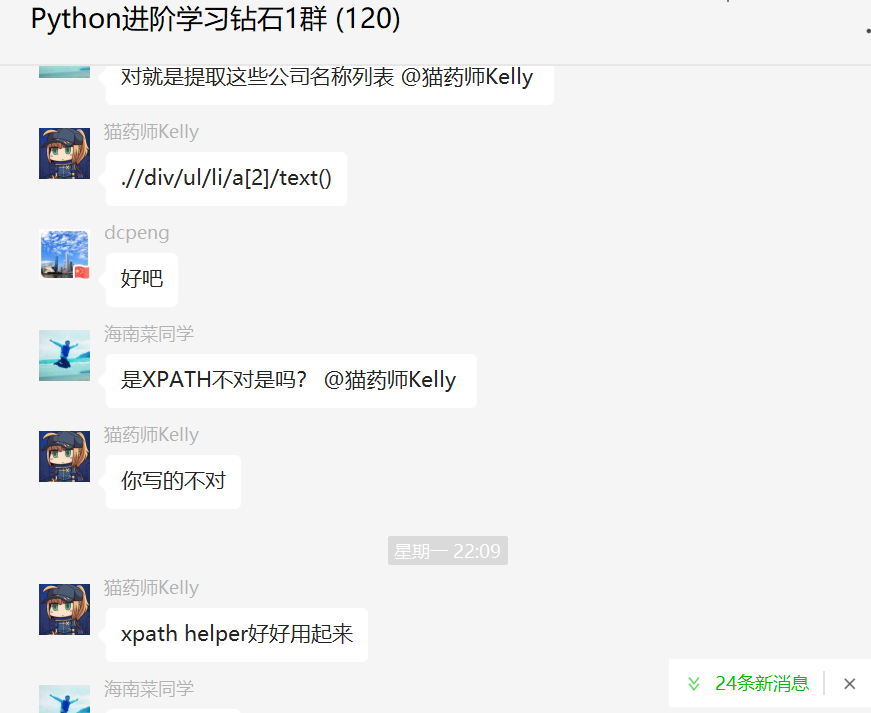
Here [Cat Pharmacist Kelly] confirmed the demand, as follows:
After modifying the extraction rules, you can get the expected text smoothly after running:
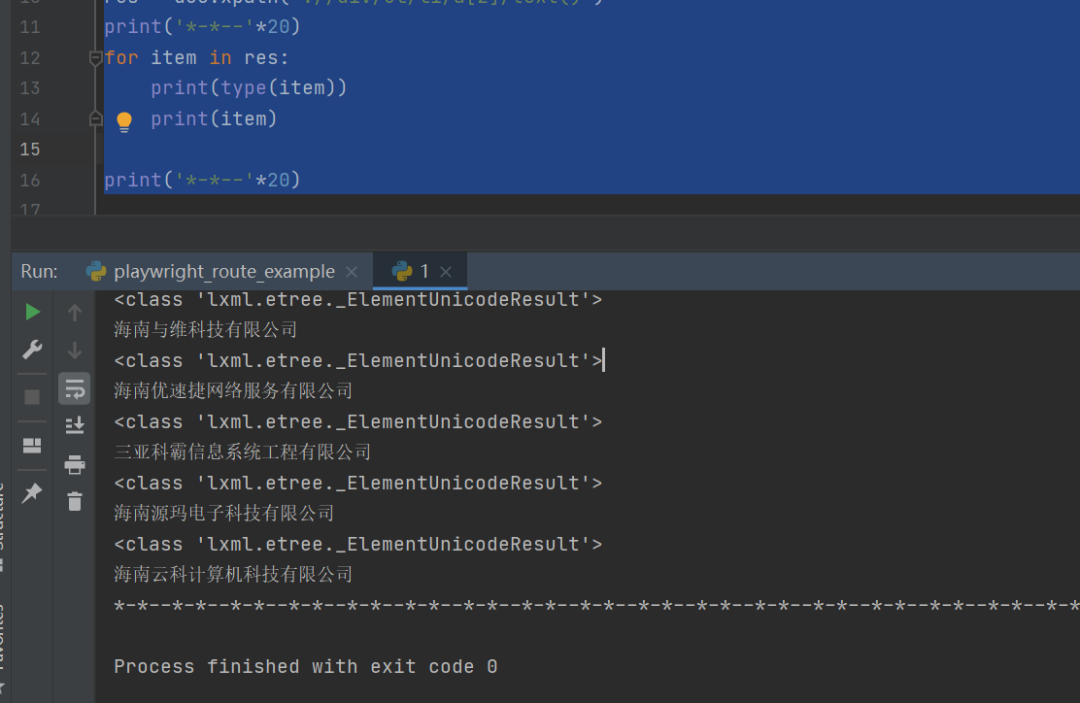
After running, you can get the desired result:
Later, the fans solved it smoothly, and the code is as follows:
from lxml import etreeimport requestsurl = "http://zw.hainan.gov.cn/wssc/emalls.html"headers = { "User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36"}html = requests.get(url,headers=headers)html = html.content.decode('utf-8')doc = etree.HTML(html)res = doc.xpath('.//div/ul/li/a[2]/text()')print('*-*--'*20)for item in res: print(type(item)) print(item)
print('*-*--'*20)
When crawling the web, remember to develop a good habit and add request headers!
- For cooperation, communication and reprint, please add WeChat moonhmily1 -