



Generally speaking, data analysis includes structured and unstructured data analysis. The former is for example structured data analysis in common list format, while the latter is for data analysis in unstructured formats such as text, images and videos. In fact, similar to structured data, plain text is also a common data format.
Text analytics extracts patterns and insights beneficial to end users by parsing unstructured text data into a more structured form using techniques such as natural language processing (NLP), information retrieval, and machine learning (ML).
Techniques such as text classification, text clustering, sentiment analysis, and similarity analysis and relationship modeling are common text analysis techniques.
For unstructured text data, we need to use the Python Natural Language Toolkit NLTK (The Python Natural Language Toolkit) for analysis. NLTK, which originated in 2001 and was originally designed for teaching, includes a text sample set called corpora. Obviously, unrolling text analysis requires us to obtain NLTK first.


01

Click the Refresh button in the lower right corner of the NLTK Downloader, and first modify the URL on the right side of the Server Index to "https://www.nltk.org/nltk_data" on the NLTK official website;
After selecting the installation package to be downloaded, click Download to download the nltk_data corpus to the "C:\Users\Administrator\AppData\Roaming\nltk_data" folder, see Figure 1.
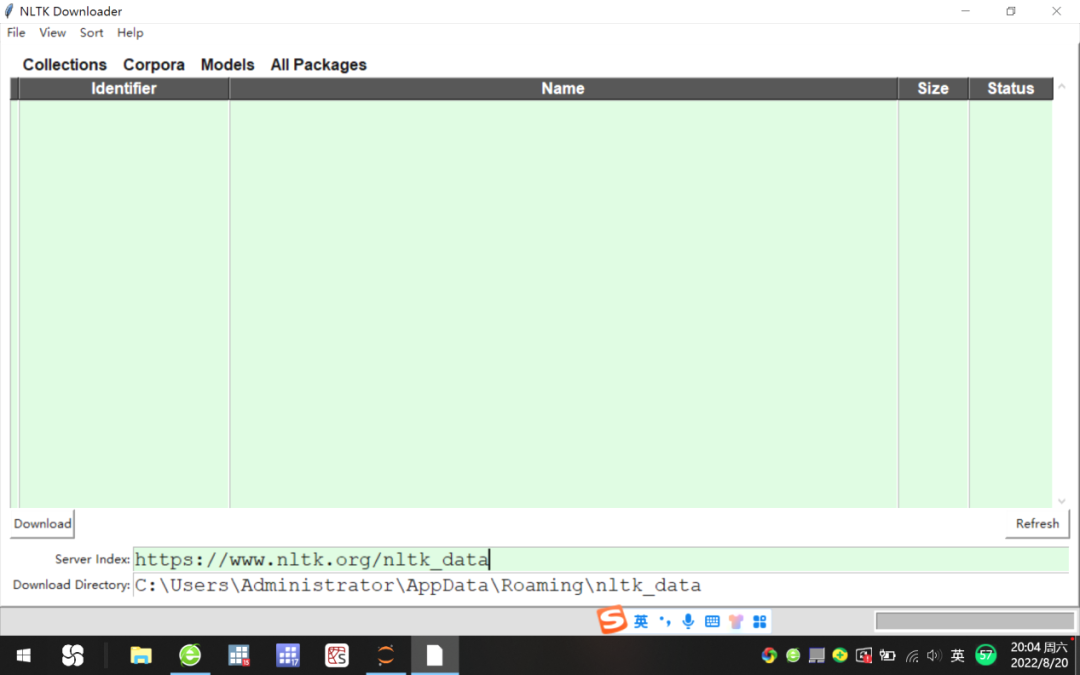
Figure 1 Download the nltk corpus from the official website
The capacity of the nltk corpus downloaded from the official website is as high as 1.8GB, and the download speed is slow. A feasible alternative is to use Baidu Cloud to download the compressed package, at the cost of manually decompressing each sub-compressed file in nltk_data.zip.

02
Enter the following file link in the search bar of the 360 browser: "https://pan.baidu.com/s/1LWM3o7iRZMF8XaD91vx9Dw", enter the dynamic verification code sent by the mobile phone to open the Baidu network disk, and then enter the extraction code "cnpf" to download Compressed package nltk_data.zip, see Figure 2.
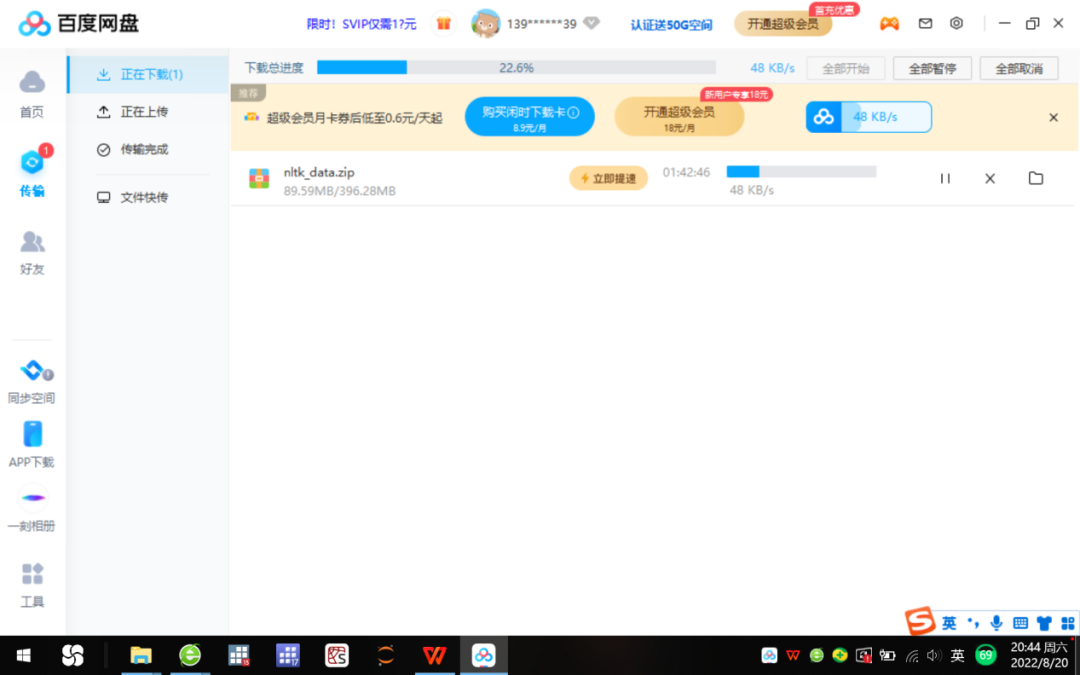
Figure 2 Baidu cloud download nltk corpus
Unzip the downloaded compressed package, you can get 9 subfolders such as chunkers, corpora, etc. We put them in the Download Directory path "C:\Users\Administrator\AppData\Roaming\nltk_data", see Figure 3.
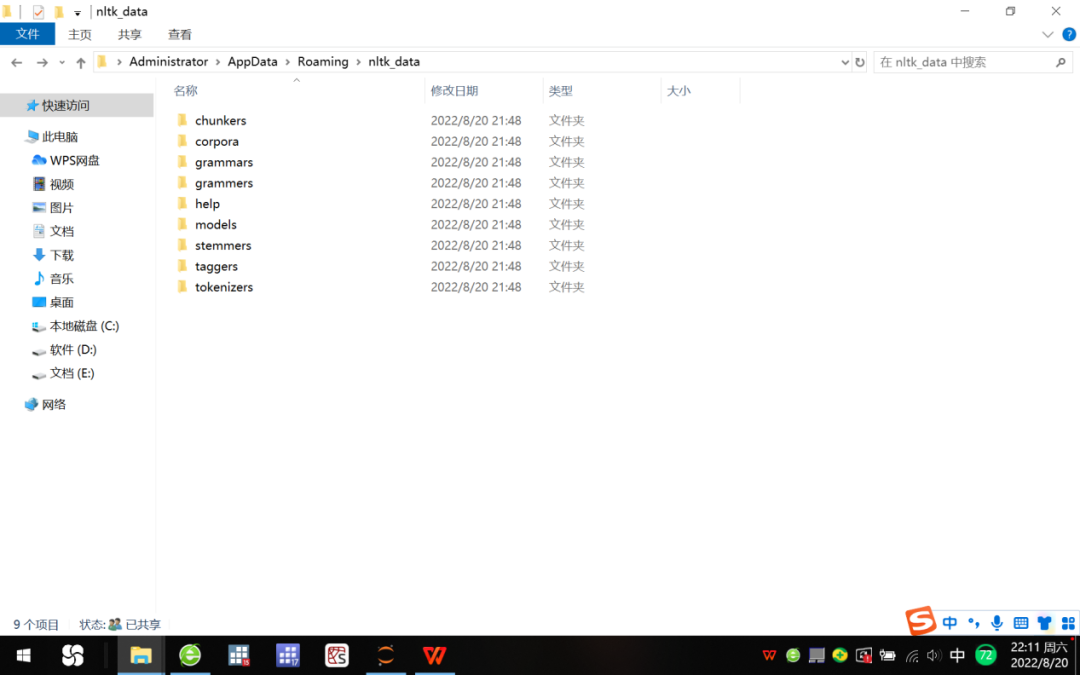
Figure 3 9 subfolders contained in the nltk_data folder
03
Open Jupyter Notebook, click the New button on the right to create a new Python file, and enter the following commands in turn to check whether the nltk corpus is downloaded successfully, see Figure 4.

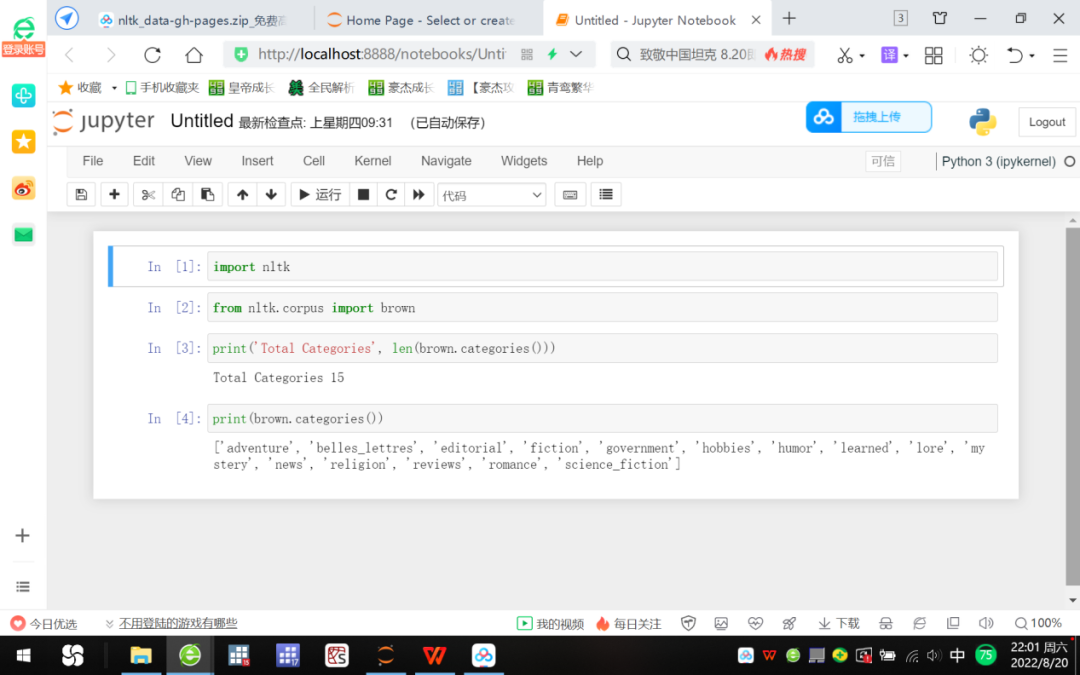
Figure 4 nltk download test: access to Brown corpus
Brown is the world's first million-level English corpus, also known as the "Contemporary American Standard Corpus of English", developed by Kucera and Francis of Brown University in 1961. The corpus consists of texts from different sources and classifications.
The command execution result in Figure 4 tells us that there are 15 types in the corpus, such as news (news), mystery (mystery), legend (fiction), etc., which indicates that the native nltk corpus has been successfully installed.
04
NLTK contains the Gutenberg Corpus, a digital library project for people to read on the Internet.
1. Unzip the gutenberg, punkt, stopwords and words compressed packages in the nltk_data subfolder corpora, see Figure 5 .
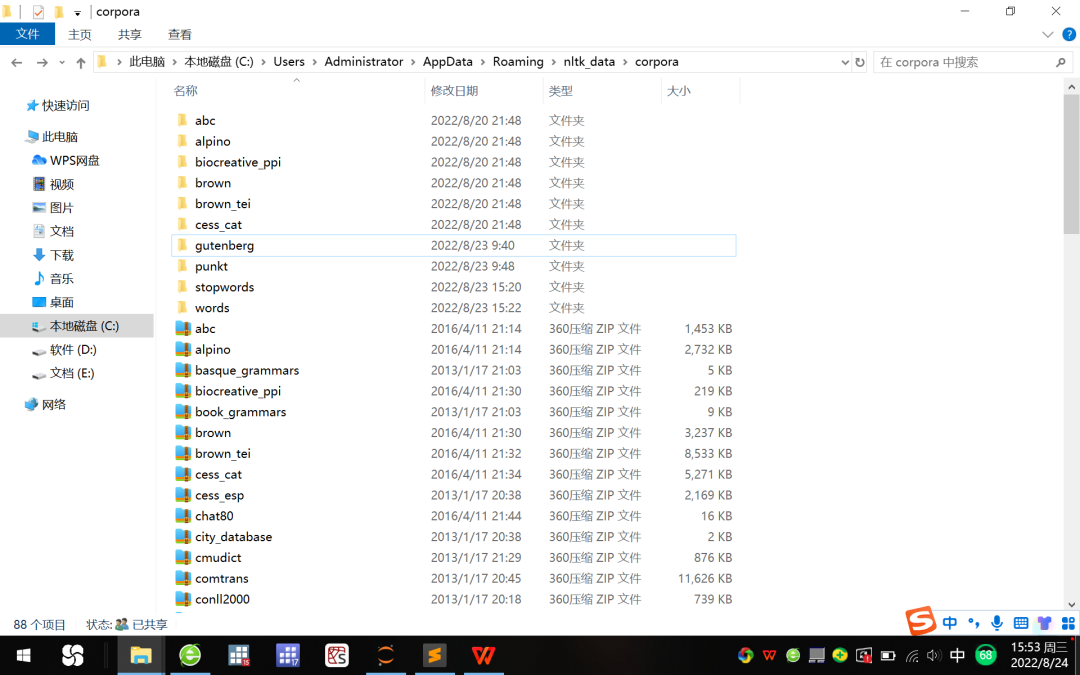
Figure 5 Decompression of the nltk_data subfolder
2. Create a new PY3 subfolder in the following path, and place the english.pickle file in this path in the newly created subfolder PY3, see Figure 6.
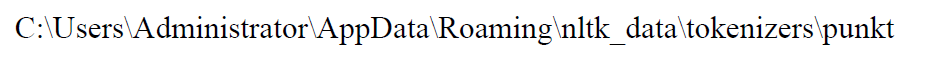
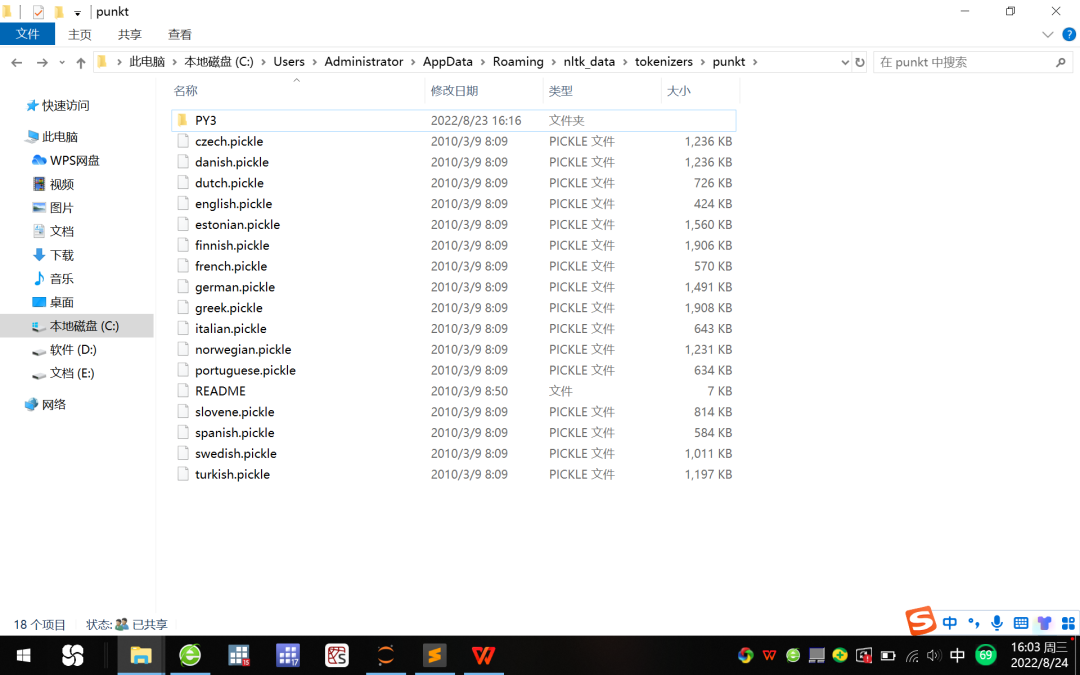
Figure 6 New subfolder PY3
3. Open Jupyter Notebook, click the New button on the right to create a new Python file, and enter the following commands in turn. See Figure 7 and Figure 8 for the running results.

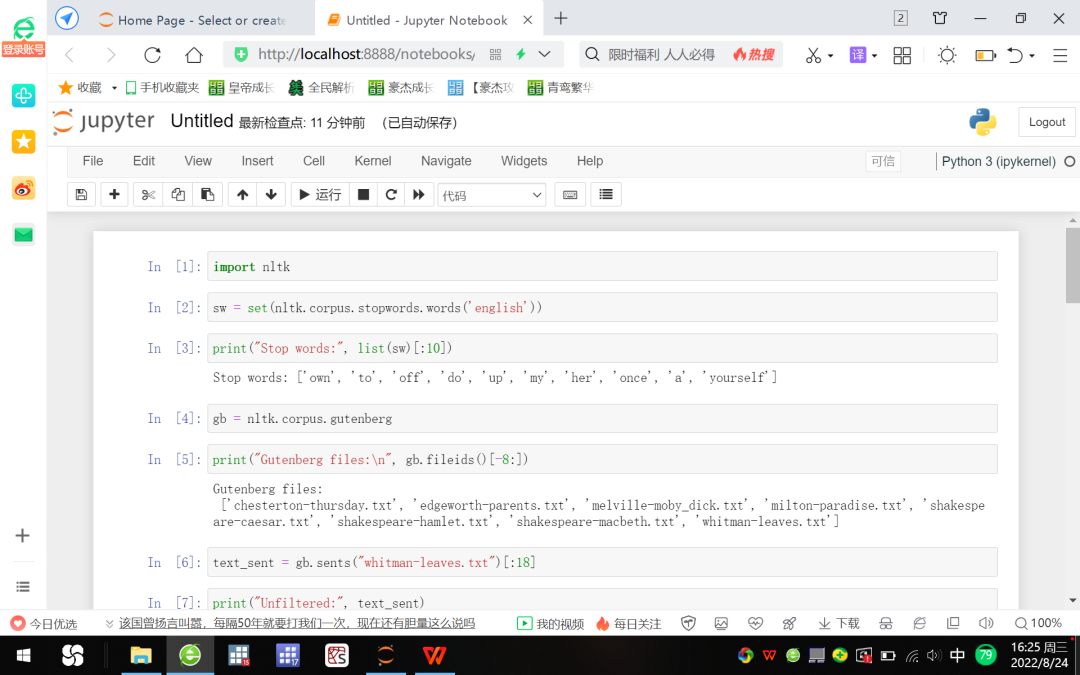
Figure 7 NLP demo based on Jupyter Notebook
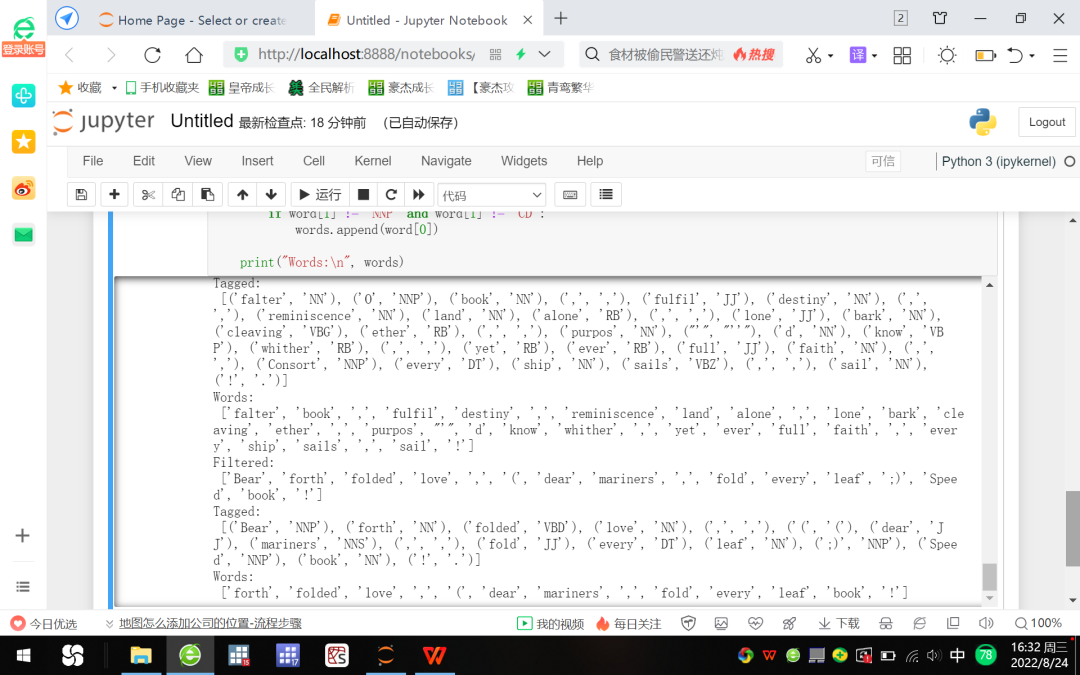
Figure 8 NLP demo for filtering out stop words, names and numbers: based on the Gutenberg project
Figure 8 shows that stop words, names, and numbers have been filtered out of the words list.

Editor: Cao Chengzhou
Review: Yang Lu

Past reviews:
Python Data Analysis Series Eight: Interconnection of Python and Stata Data Analysis
Python Data Analysis Series Seven: Multiple Regression Analysis
Python data analysis series four: data preprocessing
Python data analysis series three: descriptive statistics
Python data analysis series two: correlation operation
One of the Python data analysis series: the installation of Anaconda

Introduction to Empirical Accounting Made Easy
Scan the QR code to follow us
Dingyuan Accounting WeChat Group
Theme of this group:
Exchange Stata with Python,
Analyze structured data,
Explore unstructured text accounting,
Write the life of Dingyuan Accounting together .