When I pulled the project code from the remote repository to the local for the first time after I joined and bought the car - "What is this?!" - I was shocked and surprised.
Why am I reacting like this?
Buy a good car is a company with Ali genes, many founders and employees are from Ali. As we all know, Ali's technology is very good. Basically, it hosts some technical conferences every year, and some technical books are also written or translated by Ali people. Therefore, psychologically, there will be higher expectations for them in terms of technology. However, the reality presented to me pulled me out of my fantasy...
code maintenance
Unlike most teams, the front-end and back-end code are maintained together. Our project code is managed and maintained separately, that is, the front-end and back-end code are not in the same Git repository. The front-end code has only one warehouse, which stores the codes of different business lines such as public resources, activity pages, and main sites. Each project is a directory; the back-end code is stored in several different warehouses on a project-by-project basis. The deployment and go-live are also carried out separately.
This approach is euphemistically called "separation of front and back ends", but it is worth thinking about whether it is actually true.
Use of Git
There are two main problems teams have with Git: branch management strategies and code commit guidelines.
Branch management strategy
Every time you open Sourcetree, the first thing that catches your eye is the colorful "rainbow line"——
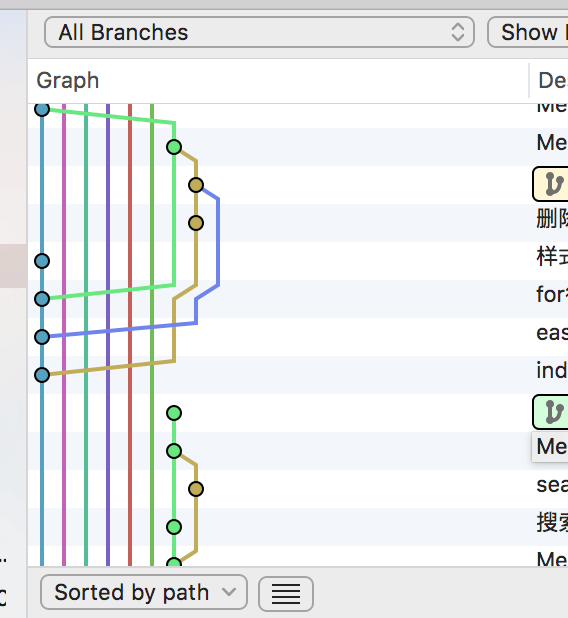
and some outdated branches --
.
└─┬─ origin
├─── dev_frontend
├─── dev_general
├─── dev_inquiry
├─── dev_maiche
├─── pub_20160111
├─── pub_20160112
├─── pub_20160113
├─── pub_20160114
├─── pub_20160128
├─── pub_20160202
└─── ...It made me feel dizzy, I don't know where to start!
The most direct reason for this situation is that there is no good branch management strategy. The branch management strategy here is as follows:
There are two fixed release days every week. Before each release day, a test engineer who manages the release (yes, we don't have an operation and maintenance engineer) will create a release branch with master a prefix prefixed on the branch. pub_The content is aggregated on this branch for testing, and then merged into the master branch for release after passing. However, that branch will not be deleted immediately after the release, but will be kept for a few weeks to avoid problems. This will leave a lot of outdated branches like in the picture above.
For some content that is not released immediately, back-end engineers will master create a dev_ prefixed branch based on the branch to develop new content.
Although they all have certain rules when creating branches, this practice produces some "garbage" branches, and makes master branches look less stable and "boom" like a time bomb!
I think Git Flow should be used in the team to manage branches. This is a branching model that has been proven by many teams, and I am confident that it can handle various scenarios that our team encounters.
Code Submission Guidelines
Our team's Git commits are very "simple", either written with a few simple letters or words, or nodes generated when merging branches, and at a glance, it is impossible to know what those people actually did. If you want to find the change record of a function point, you have to analyze it node by node.
There's a basic rule to follow when using Git - keep the commit log as concise and detailed as possible, it's like reading a book. To achieve this effect, just keep a few points in mind:
-
Control submission granularity;
-
Fill out the submission information;
-
Adjust the push frequency;
-
More spin-offs and less mergers.
To make each commit meaningful, the granularity is best controlled to a small feature or a bug fix, so that operations such as recovery can minimize "accidental injuries".
A good commit message is written in one concise sentence on the first line, followed by a blank line detailing what was added or changed in the commit:
Redirect user to the requested page after login
https://trello.com/path/to/relevant/card
Users were being redirected to the home page after login, which is less
useful than redirecting to the page they had originally requested before
being redirected to the login form.
* Store requested path in a session variable
* Redirect to the stored location after successfully logging in the userDon't push it every time you submit it, but accumulate a few more submissions and push them at one time, so as to avoid small errors in the code after the previous submission.
In order to keep the diagrams clear and the code intact, it is necessary to grasp the timing of the commit and push operations -
When it has not been pushed to the remote warehouse, if it is not necessary, just submit it and not push it, and only push it when it is necessary to cooperate with others for development. When the branch you belong to has completed its responsibilities, you need to rebase the code of the parent branch to the current branch (you must first ensure that the parent branch is up-to-date locally), then merge it into the parent branch and delete the current branch. Ideally, this branch has never been pushed once for its entire lifetime .
When it has been pushed to the remote warehouse, accumulate several submitted contents without committing. When it is time to push, first pull the code to the local, and then make several commits according to the above granularity, and then push it to the remote server. This operation process can effectively avoid unexpected problems such as lost commits caused by code conflicts, and reduce the number of commit nodes generated by merging.
Extended reading
-
http://nvie.com/posts/a-successful-git-branching-model/
-
https://robots.thoughtbot.com/5-useful-tips-for-a-better-commit-message
-
http://chris.beams.io/posts/git-commit/
Front-end engineering
Compared with the entire technical team, there are more and more serious problems in the front-end team! It can basically be summarized as follows:
-
Git repositories are a mix of many different businesses;
-
Source code reusability is low;
-
no fair use of build tools;
-
The publishing process of static resource files is cumbersome;
-
The way the event pages are written is cumbersome and not friendly to search engines.
As a front-end engineer, although I cannot do anything for the entire technical team for the time being, as a member of the front-end team, I can do what I can in the front-end team. In my opinion, "problem" means "opportunity", and it's time for me to show my skills! When I think about it, I feel a lot of adrenaline secreted, and my blood is boiling!
So, what should I do?
The things that I can think of to improve the efficiency and productivity of front-end teams are:
-
Develop specifications and conventions for coding and file storage;
-
Choose an efficient language to write source code;
-
Choose the right automation tool;
-
Ensure the smooth implementation of the above measures.
In order to improve the overall quality and strength of the front-end team, there is still a lot that needs to be done. If you want to complete these things overnight, the road to front-end engineering optimization is a long way to go...
There will be a lot of resistance to transforming existing projects. Fortunately, the company's business expansion needs to develop new projects at this time. Decided to start with this new project, tried a small knife, summed up a set of plans and implemented rectification to other projects.
Taking this article as a reference, we will write several articles about our front-end team building in the future, so stay tuned!