
Introduction: As a very practical language in daily development and production, it is necessary to master some python usage, such as crawler, network request and other scenarios, which is very practical. But python is single-threaded. How to improve the processing speed of python is a very important issue. A key technology of this problem is called coroutine. This article talks about the understanding and use of python coroutines, mainly to sort out the network request module, hoping to help students in need.
Before understanding the concept of coroutine and its role scenarios, we must first understand a few basic concepts about the operating system, mainly process, thread, synchronization, asynchrony, blocking, non-blocking. Understanding these concepts is not only for coroutines This scenario, such as message queues, caches, etc., all have certain help. Next, the editor makes a summary of his own understanding and the materials inquired on the Internet.
During the interview, we will all remember the concept that a process is the smallest unit of system resource allocation. Yes, the system consists of a program, that is, a process. Generally, it is divided into a text area, a data area and a stack area.
The text area stores the code (machine code) executed by the processor, generally speaking, this is a read-only area that prevents the running program from being accidentally modified.
The data area stores all variables and dynamically allocated memory, and is subdivided into initialized data areas (all initialized global, static, constant, and external variables) and initialized data areas (global variables and static variables initialized to 0) ), the initialized variables are initially stored in the text area, and are copied to the initialized data area after the program is started.
The stack area stores the instructions and local variables of the active procedure call. In the address space, the stack area is closely connected to the heap area. Their growth directions are opposite, and the memory is linear, so our code is placed at a low address, from low to low. High growth, the size of the stack area is unpredictable, and it can be used at any time, so it is placed at a high address and grows from high to low. When the heap and stack pointers overlap, it means that the memory is exhausted, resulting in a memory overflow.
The creation and destruction of processes are relative to system resources, consume resources very much, and are a relatively expensive operation. In order for a process to run itself, it must preemptively compete for the CPU. For a single-core CPU, only the code of one process can be executed at the same time, so implementing multiple processes on a single-core CPU is to switch between different processes quickly through the CPU, which looks like multiple processes are running at the same time.
Since the processes are isolated and each has its own memory resources, it is relatively safe compared to the shared memory of threads. Data between different processes can only be communicated and shared through IPC (Inter-Process Communication).
A thread is the smallest unit of CPU scheduling. If the process is a container, the thread is the program running in the container, the thread belongs to the process, and multiple threads of the same process share the memory address space of the process.
Communication between threads can be directly communicated through global variables, so relatively speaking, communication between threads is not very safe, so various lock scenarios are introduced, which will not be described here.
When a thread crashes, it will cause the entire process to crash, that is, other threads also hang, but multi-process does not, one process hangs, and the other process still runs.
In a multi-core operating system, there is only one thread in the default process, so multi-process processing is like one process and one core.
synchronous and asynchronous
Synchronous and asynchronous focus on the message communication mechanism. The so-called synchronization means that when a function call is issued, the call will not return until the result is obtained. Once the call returns, the return value of the execution is immediately obtained, that is, the caller actively waits for the result of the call. The so-called asynchronous means that after the request is sent, the call returns immediately without returning a result, and the actual result of the call is notified through callbacks and other methods.
Synchronous requests need to actively read and write data and wait for the results; for asynchronous requests, the caller will not get the results immediately. Instead, after the call is made, the callee notifies the caller through status, notification, or handles the call through a callback function.
blocking and non-blocking
Blocking and non-blocking focus on the state of the program while waiting for the result of the call (message, return value).
A blocking call means that the current thread is suspended until the result of the call is returned. The calling thread does not return until it has the result. A non-blocking call means that the call will not block the current thread until the result is not immediately available. Therefore, the distinguishing condition is whether the data to be accessed by the process/thread is ready and whether the process/thread needs to wait.
Non-blocking is generally implemented through multiplexing, and multiplexing has several implementation methods: select, poll, and epoll.
After understanding the previous concepts, let's look at the concept of coroutines.
Coroutines belong to threads, also known as microthreads, fibers, and the English name is Coroutine. For example, when executing function A, I want to interrupt the execution of function B at any time, and then interrupt the execution of B and switch back to executing A. This is the role of coroutines, which are freely switched by the caller. This switching process is not equivalent to a function call because it has no call statement. The execution method is similar to multi-threading, but the coroutine is executed by only one thread.
The advantage of coroutines is that the execution efficiency is very high, because the switching of coroutines is controlled by the program itself, and there is no need to switch threads, that is, there is no overhead of switching threads. At the same time, since there is only one thread, there is no conflict problem, and there is no need to rely on locks (locking and releasing locks consume a lot of resources).
The main usage scenario of coroutines is to process IO-intensive programs and solve efficiency problems, and is not suitable for processing CPU-intensive programs. However, there are many of these two scenarios in actual scenarios. If you want to make full use of CPU utilization, you can combine multi-process + coroutine. We'll talk about junctions later.
According to wikipedia, a coroutine is a non-priority subroutine scheduling component that allows subroutines to suspend and resume at specific locations. So in theory, as long as there is enough memory, there can be any number of coroutines in a thread, but only one coroutine can be running at the same time, and multiple coroutines share the computer resources allocated by the thread. Coroutines are to give full play to the advantages of asynchronous calls, and asynchronous operations are to avoid IO operations blocking threads.
Before understanding the principle, we first do a knowledge preparation.
1) Modern mainstream operating systems are almost all time-sharing operating systems, that is, a computer uses time slice rotation to serve multiple users. The basic unit of system resource allocation is process, and the basic unit of CPU scheduling is thread.
2) The runtime memory space is divided into variable area, stack area and heap area. In memory address allocation, the heap area is from low to high, and the stack area is from high to low.
3) When the computer executes, one instruction is read and executed. When the current instruction is executed, the address of the next instruction is in the IP of the instruction register, the ESP register value points to the current stack top address, and EBP points to the base address of the current active stack frame.
4) When a function call occurs in the system, the operation is: first push the input parameters from right to left on the stack, then push the return address onto the stack, and finally push the current value of the EBP register onto the stack, modify the value of the ESP register, and allocate the current value in the stack area. Space required for function local variables.
5) The context of the coroutine contains the values stored in the stack area and registers belonging to the current coroutine.
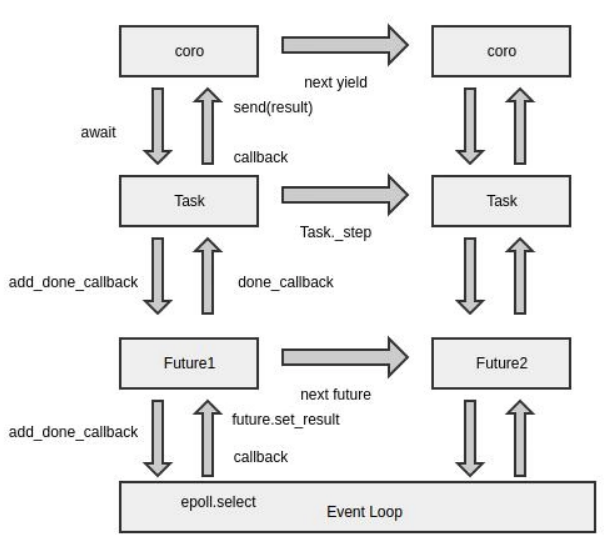
In python3.3, coroutines are used through the keyword yield from. In 3.5, the syntactic sugars async and await for coroutines are introduced. We mainly look at the principle analysis of async/await. Among them, the event loop is the core. Students who have written js will know more about the event loop. The event loop is a programming architecture that waits for the program to allocate events or messages (Wikipedia). In python, the asyncio.coroutine decorator is used to mark functions as coroutines, where coroutines are used with asyncio and its event loop, and in subsequent development, async/await is used more and more widely.
Async/await is the key to using python coroutines. From a structural point of view, asyncio is essentially an asynchronous framework, and async/await is an API provided for asynchronous frameworks that is convenient for users to call, so users want to use async/await to write Coroutine code must currently use asyncio or other asynchronous libraries.
In the actual development and writing of asynchronous code, in order to avoid the callback hell caused by too many callback methods, but also need to obtain the return result of the asynchronous call, the smart language designer designed an object called Future, which encapsulates the interaction with the loop. Behavior. The general execution process is: after the program starts, register the callback function with epoll through the add_done_callback method, when the result attribute gets the return value, actively run the previously registered callback function, and pass it up to the coroutine. This Future object is asyncio.Future.
However, in order to obtain the return value, the program must restore the working state, and because the life cycle of the Future object itself is relatively short, the work may have been completed after each registration callback, event generation, and triggering of the callback process, so use Future to send to the generator. result is not appropriate. Therefore, a new object Task is introduced here, which is stored in the Future object to manage the state of the generator coroutine.
Another Future object in Python is concurrent.futures.Future, which is incompatible with asyncio.Future and is prone to confusion. The difference is that concurrent.futures is a thread-level Future object. When using concurrent.futures.Executor for multi-threaded programming, this object is used to pass results between different threads.
As mentioned above, Task is a task object that maintains the state processing and execution logic of the generator coroutine. There is a _step method in Task, which is responsible for the state transition of the interaction process between the generator coroutine and EventLoop. The whole process can be understood as: Task to The coroutine sends a value, restoring its working state. When the coroutine runs to the breakpoint, a new Future object is obtained, and then the callback registration process of future and loop is processed.
In daily development, there is a misunderstanding that each thread can have an independent loop. When actually running, the main thread can create a new loop through asyncio.get_event_loop(), but in other threads, using get_event_loop() will throw an error. The correct way is to explicitly bind the current thread to the loop of the main thread through asyncio.set_event_loop().
Loop has a big flaw, that is, the running state of loop is not controlled by Python code, so in business processing, it is impossible to stably extend the coroutine to run in multiple threads.
After introducing the concepts and principles, let me see how to use it. Here, let's take an example of a practical scenario to see how to use python's coroutines.
Some files are received externally, and each file contains a set of data. Among them, this set of data needs to be sent to a third-party platform through http, and the result can be obtained.
Since each set of data in the same file has no processing logic before and after, the network request sent through the Requests library is executed serially, and the next set of data needs to wait for the return of the previous set of data, which shows the processing time of the entire file. Long, this request method can be completely implemented by coroutines.
In order to cooperate with the coroutine to send requests more conveniently, we use the aiohttp library instead of the requests library. Regarding aiohttp, we will not do too much analysis here, but only give a brief introduction.
aiohttp is an asynchronous HTTP client/server of asyncio and Python. Because it is asynchronous, it is often used to receive requests on the server side, and to initiate asynchronous requests with the client crawler application. Here we mainly use it to send requests.
aiohttp supports client and HTTP server, can realize single-threaded concurrent IO operation, supports Server WebSockets and Client WebSockets without using Callback Hell, and has middleware.
Go directly to the code, talk is cheap, show me the code~
import aiohttpimport asynciofrom inspect import isfunctionimport timeimport logger
@logging_utils.exception(logger)def request(pool, data_list): loop = asyncio.get_event_loop() loop.run_until_complete(exec(pool, data_list))
async def exec(pool, data_list): tasks = [] sem = asyncio.Semaphore(pool) for item in data_list: tasks.append( control_sem(sem, item.get("method", "GET"), item.get("url"), item.get("data"), item.get("headers"), item.get("callback"))) await asyncio.wait(tasks)
async def control_sem(sem, method, url, data, headers, callback): async with sem: count = 0 flag = False while not flag and count < 4: flag = await fetch(method, url, data, headers, callback) count = count + 1 print("flag:{},count:{}".format(flag, count)) if count == 4 and not flag: raise Exception('EAS service not responding after 4 times of retry.')
async def fetch(method, url, data, headers, callback): async with aiohttp.request(method, url=url, data=data, headers=headers) as resp: try: json = await resp.read() print(json) if resp.status != 200: return False if isfunction(callback): callback(json) return True except Exception as e: print(e)
Here, we encapsulate the request method for sending batch requests to the outside world, receive how much data to send at one time, and integrate the data. When using it externally, we only need to construct the data of the network request object, set the size of the request pool, and at the same time , the retry function is set, and 4 retries are performed to prevent the network request of a single data from failing to be sent when the network is shaking.
After using the coroutine to reconstruct the network request module, when the amount of data is 1000, it is doubled from the previous 816s to 424s, and when the size of the request pool is increased, the effect is more obvious. For the connection data limit, we set a threshold of 40. As you can see, the degree of optimization is significant.
Life is too short, I use python. Whether the coroutine is good or not, whoever uses it knows. If there is a similar scenario, you can consider enabling it, or other scenarios, please leave a message for discussion.
1. Understand async/await:
https://segmentfault.com/a/1190000015488033?spm=ata.13261165.0.0.57d41b119Uyp8t
2. Coroutine concept and principle (c++ and node.js implementation)
https://cnodejs.org/topic/58ddd7a303d476b42d34c911?spm=ata.13261165.0.0.57d41b119Uyp8t
3. How to speed up Python crawler? Asynchronous, coroutine or multi-process? Share a common practice that Xiaobai can understand.
Recommend a good place to learn Python
365 days, full-course accompaniment learning

Click the image below to read
Python library
Send: 106 books, receive spree: 106 Python e-books.
119 original content
the public
👇Click to read the original text and watch 60 sets of Python video tutorials for free ~
Heavy! Ali has launched free Python video tutorials and free cloud servers!


