
Machine learning is developing rapidly, but the understanding of theoretical knowledge cannot keep up? This article will give reflections from a data scientist who uses the utility matrix to sort out the relationship between the experimental results of the model and the underlying theory, and explore the progress of various subfields of machine learning.
introduce
Original blog post
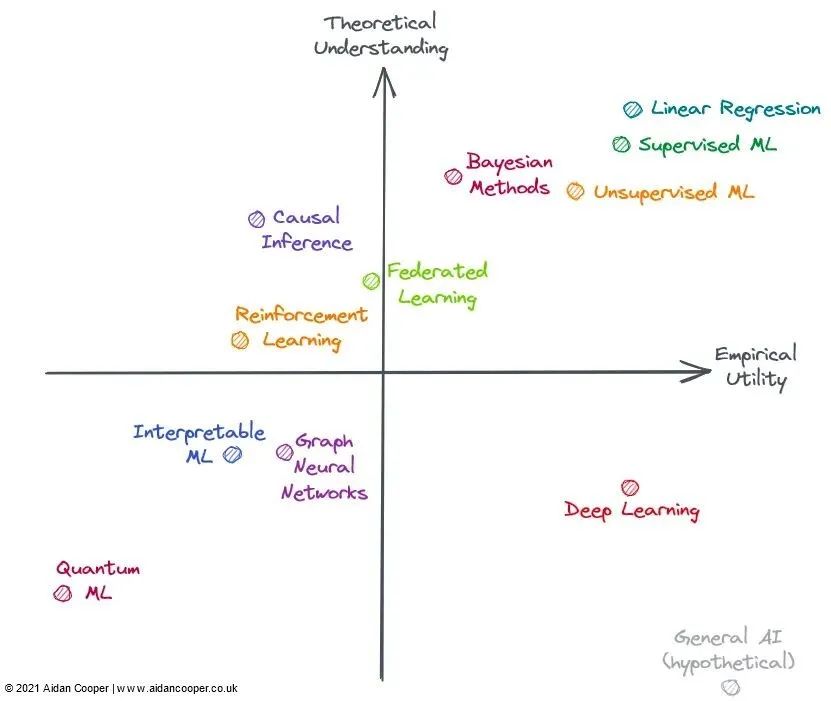
The field of machine learning in 2022
Upper right quadrant: high understanding, high utility
Lower right quadrant: low understanding, high utility
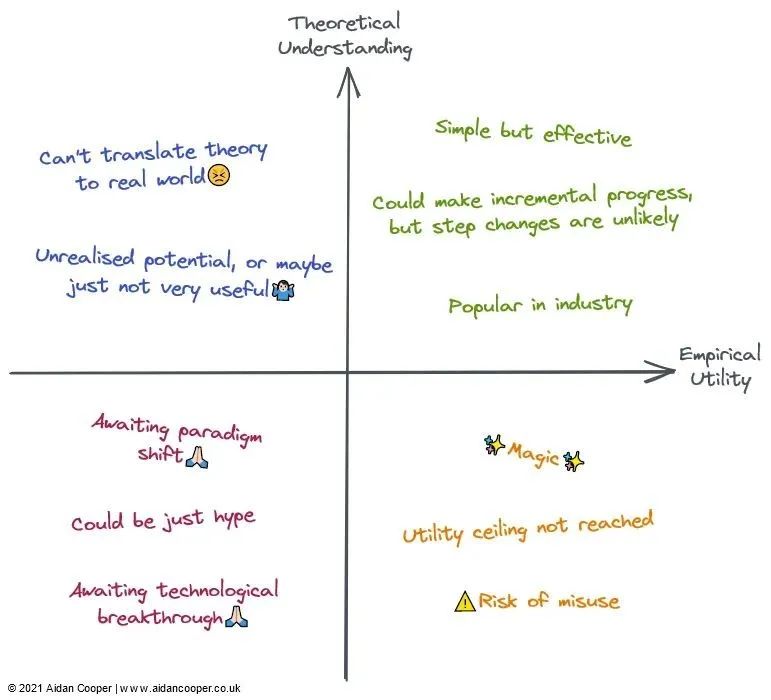
Upper left quadrant: high understanding, low utility
Lower left quadrant: low understanding, low utility
Incremental advancements, technological leaps and paradigm shifts
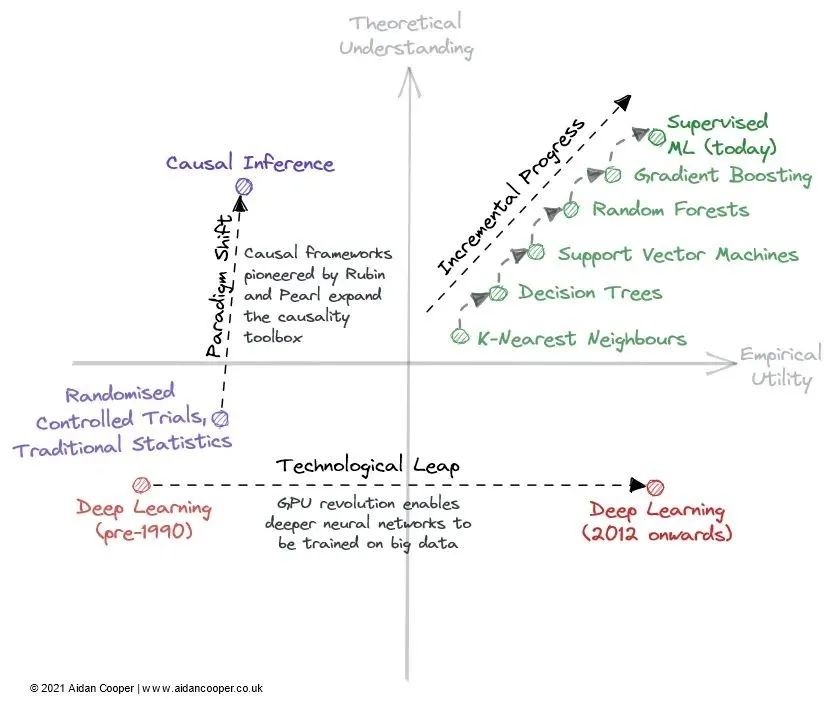
The Scientific Revolution in Prediction and Deep Learning
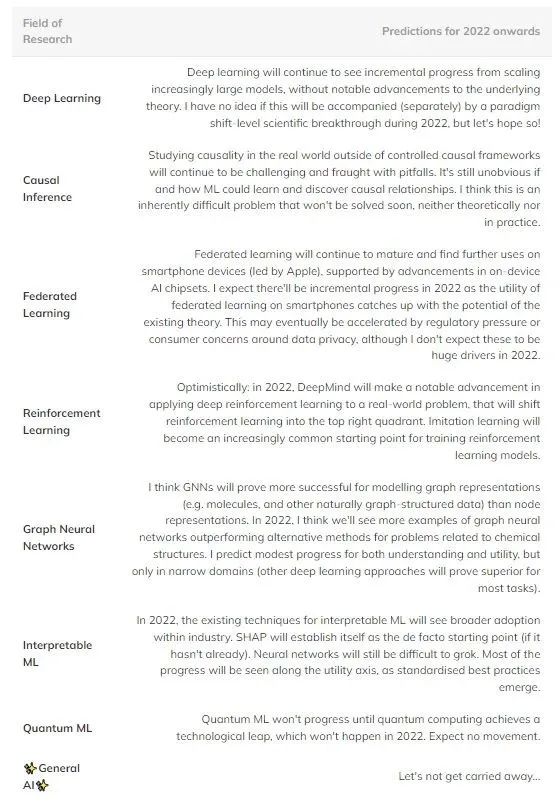
Table 1: Prediction of future progress in several major fields of machine learning.
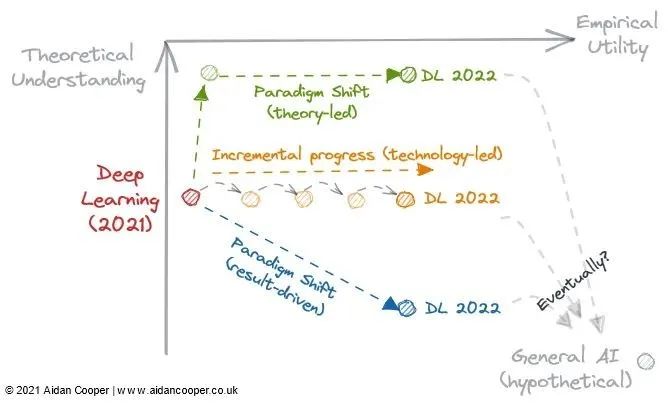
Figure 3: 3 potential trajectories of deep learning development in 2022.
-
Will theoretical breakthroughs allow our understanding to catch up with practicality and transform deep learning into a more structured discipline like traditional machine learning?
-
Is the existing deep learning literature enough for the utility to increase indefinitely, just by scaling larger and larger models?
-
Or will an empirical breakthrough lead us further down the rabbit hole into a new paradigm of enhanced utility, even though we know less about it?
-
Do any of these routes lead to artificial general intelligence?
The main work of the Future Intelligence Laboratory includes: establishing an AI intelligent system IQ evaluation system, and carrying out the world artificial intelligence IQ evaluation; carrying out the Internet (city) brain research plan, building Internet (city) brain technology and enterprise maps, in order to improve enterprises, industries and industries. Smart level services for cities. A daily recommendation of learning articles covering future technological trends. At present, the online platform has collected thousands of cutting-edge scientific and technological articles and reports.
If you are interested in laboratory research, welcome to join the Future Intelligent Laboratory online platform. Scan the QR code below or click "Read the original text" in the lower left corner of this article
