
Recommended in the past
Add, delete, search and modify in Pandas
Install
pip install pandasTable of contents
1. The use of Pandas at work
2. Common functions
1. The use of Pandas at work
2. Common functions
Create an excel file first
import pandas as pddata = {'city': ['北京', '上海', '广州', '深圳'],'2018': [33105, 36011, 22859, 24221]}data = pd.DataFrame(data)data.to_excel('excel练习.xlsx', index=False)
2.1, read data
df = pd.read_excel('excel练习.xlsx')print(df)print(type(df))print(df.values)print(type(df.values))
operation result:
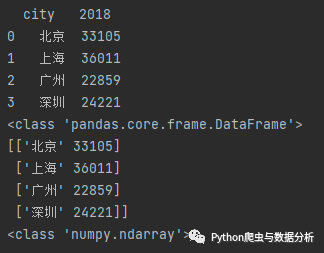
Figure 2-1
Notice:

Figure 2-2
pd.read_excel(file_path, converters={'编号': str})read data from a column
df = pd.read_excel('excel练习.xlsx')data = df['city']print(data)
operation result:
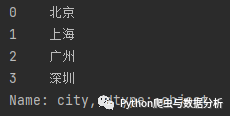
Figure 2-3
2.2. Store data
data = {'city': ['北京', '上海', '广州', '深圳'],'2018': [33105, 36011, 22859, 24221]}data = pd.DataFrame(data)data.to_excel('excel练习.xlsx', index=False)
2.3. Delete data
2.3.1, delete a row containing a value
data = df[df.city != '深圳']operation result:
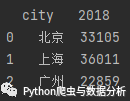
Figure 2-4
2.3.2, delete the specified line drop()
data = df.drop([0, 1], axis=0)delete lines 0 and 1
operation result:
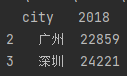
Figure 2-5
2.3.3, delete the specified column drop()
data = df.drop(['2018'], axis=1)operation result:
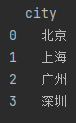
Figure 2-6
2.3.4, deduplication drop_duplicates()
data.drop_duplicates(['city'])data.drop_duplicates(['city', '2018'], keep='last')
2.3.5, go to 0 value
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川', '未知', 0],'2018': [33105, 36011, 22859, 24221, np.nan, 0, 0]}data2 = pd.DataFrame(data2)# 方法一df = data2[(data2.T != 0).any()]# 方法二df2 = data2.loc[(data2 != 0).any(1)]print(df)print('==================')print(df2)
operation result:
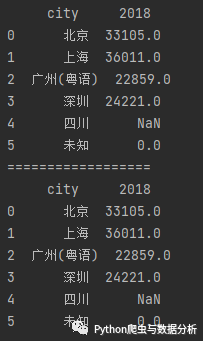
Figure 2-7
explain:
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川', '未知', 0],'2018': [33105, 36011, 22859, 24221, np.nan, 0, 0]}data2 = pd.DataFrame(data2)df = (data2.T != 0).any()
operation result:
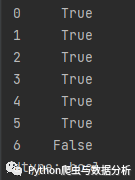
Figure 2-8
If the specified column has a value of 0, the entire row will be deleted, and you can refer to 2.3.1.
2.3.6, remove the null value dropna()
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川'],'2018': [33105, 36011, 22859, 24221, np.nan]}data2 = pd.DataFrame(data2)print(data2.dropna())
operation result:
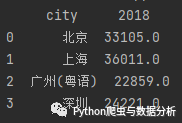
Figure 2-9
data2 = {'city': ['北京', '上海', '广州(粤语)', '深圳', '四川'],'2018': [33105, 36011, 22859, 24221, np.nan]}data2 = pd.DataFrame(data2)print(data2.dropna(axis=1))
operation result:
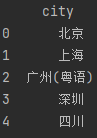
Figure 2-10
2.4. Additional data

Recommended in the past
Add, delete, check and modify pandas
By the way, after reading it, remember to click three times, this is really important to me.