Surprise at the end
1 2.6 Neural Network Regression Algorithm
12.6.1 Classes, Parameters, Properties, and Methods
kind
class sklearn.neural_network.MLPRegressor(hidden_layer_sizes=100, activation='relu', *, solver='adam', alpha=0.0001, batch_size='auto', learning_rate='constant', learning_rate_init=0.001, power_t=0.5, max_iter=200, shuffle=True, random_state=None, tol=0.0001, verbose=False, warm_start=False, momentum=0.9, nesterovs_momentum=True, early_stopping=False, validation_fraction=0.1, beta_1=0.9, beta_2=0.999, epsilon=1e-08, n_iter_no_change=10, max_fun=15000)parameter
|
parameter |
explain |
|
hidden_layer_sizes |
tuple, length = n_layers - 2, default=(100,) The ith element represents the number of neurons in the ith hidden layer. |
|
activation |
{'identity', 'logistic', 'tanh', 'relu'}, default='relu' Activation function for the hidden layer. 'identity' , no-op activation, used to implement a linear bottleneck, returns f(x) = x 'logistic' , the logistic sigmoid function, returns f(x) = 1 / (1 + exp(-x)) . 'tanh' , the hyperbolic tan function, returns f(x) = tanh(x) . 'relu' is the corrected linear unit function, returning f(x) = max(0 , x) |
|
solver |
{'lbfgs', 'sgd', 'adam'}, default='adam' weight optimization solver. 'lbfgs' is an optimizer in the family of quasi-Newton methods. 'sgd' refers to Stochastic Gradient Descent. 'adam' refers to the gradient-based stochastic optimizer proposed by Jinma, Dideric, and Jimmyba Note : In terms of training time and validation scores, the default solver 'adam' works well on relatively large datasets ( with thousands or more training samples ) works reasonably well. However, for small datasets, 'lbfgs' can converge faster and perform better. |
|
alpha |
float, default=0.0001 . L2 penalty ( regular term ) parameter. |
Attributes
|
Attributes |
category |
introduce |
|
loss_ |
float |
Current loss calculated with the loss function. |
|
best_loss_ |
float |
The minimum loss achieved by the solver during the entire fitting process. |
|
loss_curve_ |
list of shape (n_iter_,) |
The ith element in the list represents the loss for the ith iteration. |
|
t_ |
int |
The number of training samples seen by the solver during fitting. |
|
coefs_ |
list of shape (n_layers - 1,) |
The ith element in the list represents the weight matrix corresponding to the ith layer. |
|
intercepts_ |
list of shape (n_layers - 1,) |
The ith element in the list represents the bias vector corresponding to layer i+1 . |
|
n_iter_ |
int |
The number of iterations the solver has run. |
|
n_layers_ |
int |
layers. |
|
n_outputs_ |
int |
number of outputs. |
|
out_activation_ |
str |
The name of the output activation function. |
|
loss_curve_ |
list of shape (n_iters,) |
The loss value is evaluated at the end of each training step. |
|
t_ |
int |
Mathematically equal to n iters*X.shape[0] , representing the time step, used by the optimizer's learning rate scheduler. |
method
|
fit(X, y) |
Fit the model to the data matrix X and target y . |
|
get_params([deep]) |
Get the parameters for this estimator. |
|
predict(X) |
A multi-layer perceptron model is used for prediction. |
|
score(X, y[, sample_weight]) |
Returns the predicted coefficient of determination R2 . |
|
set_params(**params) |
Set the parameters for this estimator. |
12.6.2 Neural Network Regression Algorithms
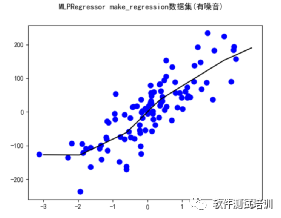
def MLPRegressor_make_regression():warnings.filterwarnings("ignore")myutil = util()X,y = datasets.make_regression(n_samples=100,n_features=1,n_informative=2,noise=50,random_state=8)X_train,X_test,y_train,y_test = train_test_split(X, y, random_state=8,test_size=0.3)clf = MLPRegressor(max_iter=20000).fit(X,y)title = "MLPRegressor make_regression数据集(有噪音)"myutil.draw_line(X[:,0],y,clf,title)
def My_MLPRegressor(solver,hidden_layer_sizes,activation,level,alpha,mydata,title):warnings.filterwarnings("ignore")myutil = util()X,y = mydata.data,mydata.targetX_train,X_test,y_train,y_test = train_test_split(X, y, random_state=8,test_size=0.3)clf = MLPRegressor(solver=solver,hidden_layer_sizes=hidden_layer_sizes,activation=activation,alpha=alpha,max_iter=10000).fit(X_train,y_train)mytitle = "MLPRegressor("+title+"):solver:"+solver+",node:"+str(hidden_layer_sizes)+",activation:"+activation+",level="+str(level)+",alpha="+str(alpha)myutil.print_scores(clf,X_train,y_train,X_test,y_test,mytitle)def MLPRegressor_base():mydatas = [datasets.load_diabetes(), datasets.load_boston()]titles = ["糖尿病数据","波士顿房价数据"]for (mydata,title) in zip(mydatas, titles):ten = [10]hundred = [100]two_ten = [10,10]Parameters = [['lbfgs',hundred,'relu',1,0.0001], ['lbfgs',ten,'relu',1,0.0001], ['lbfgs',two_ten,'relu',2,0.0001],['lbfgs',two_ten,'tanh',2,0.0001],['lbfgs',two_ten,'tanh',2,1]]for Parameter in Parameters:My_MLPRegressor(Parameter[0],Parameter[1],Parameter[2],Parameter[3],Parameter[4],mydata,title)
output
MLPRegressor(糖尿病数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:68.83%MLPRegressor(糖尿病数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:28.78%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:53.50%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:45.41%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:68.39%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:31.62%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:64.18%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:31.46%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:-0.00%MLPRegressor(糖尿病数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:-0.01%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:90.04%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[100],activation:relu,level=1,alpha=0.0001:63.90%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:85.23%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10],activation:relu,level=1,alpha=0.0001:68.49%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:90.12%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:relu,level=2,alpha=0.0001:63.48%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:18.19%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=0.0001:18.25%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:85.37%MLPRegressor(波士顿房价数据):solver:lbfgs,node:[10, 10],activation:tanh,level=2,alpha=1:
73.75%
|
data |
solver |
node |
activation |
level |
alpha |
training score |
test score |
|
diabetes |
lbfgs |
[100] |
relu |
1 |
0.0001 |
68.83% |
28.78% |
|
lbfgs |
[10] |
relu |
1 |
0.0001 |
53.50% |
45.41% |
|
|
lbfgs |
[10,10] |
relu |
2 |
0.0001 |
68.39% |
31.62% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
0.0001 |
64.18% |
31.46% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
1 |
-0.00% |
-0.00% |
|
|
Boston house prices |
lbfgs |
[100] |
relu |
1 |
0.0001 |
90.04% |
63.90% |
|
lbfgs |
[10] |
relu |
1 |
0.0001 |
85.23% |
68.49% |
|
|
lbfgs |
[10,10] |
relu |
2 |
0.0001 |
90.12% |
63.48% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
0.0001 |
18.19% |
18.25% |
|
|
lbfgs |
[10,10] |
tanh |
2 |
1 |
85.37% |
73.75% |
Surprise at the end of the article
Penetration testing environment and code
Experimental code:
Link: https://pan.baidu.com/s/14XsCng6laiSiT_anuwr5dw?pwd=78dy
Extraction code: 78dy
surroundings
Install tomcat, Apache and MySQL on Windows
Install tomcat, Apache and MySQL on Linux
operate
1. Copy the sec in tomcat to the tomcat directory, such as %TOMCAT-HOME%\webapps\
2. Copy the sec in Apache to the Apache directory, such as \htdocs\
3. Under the sec directory in tomcat
include.jsp
<%StringWindows_IP="127.0.0.1";StringLinux_IP="192.168.0.150";StringJSP_PORT="8080";StringPHP_PORT="8100";%>
-
String Windows_IP: IP address of Windows
-
String Linux_IP: IP address of Linux
-
String JSP_PORT: The port number of the JSP
-
String PHP_PORT: The port number of PHP
3. Include.php in the sec directory in Apache
$windows_ip="http://127.0.0.1";$linux_ip="http://192.168.0.150";$jsp_port="8080";$php_port="8100";?>
-
$windows_ip: IP address of Windows
-
$linux_ip=: IP address of Linux
-
$jsp_port=: The port number of the JSP
-
$php_port: The port number of PHP
Open browse and enter http://192.168.0.106:8080/sec/
192.168.0.106 is the local IP address
Database configuration
Create a sec database under MySQL, root/123456. Import 4 csv files under DB into sec database
Penetration testing operating system virtual machine file vmx file
1) Windows 2000 Professional
Link: https://pan.baidu.com/s/13OSz_7H1mIpMKJMq92nEqg?pwd=upsm
Extraction code: upsm
2) Windows Server 2003 Standard x64 Edition
Link: https://pan.baidu.com/s/1Ro-BoTmp-1kq0W_lB9Oiww?pwd=ngsb
Extraction code: ngsb
Power-on password: 123456
3) Windows 7 x64
Link: https://pan.baidu.com/s/1-vLtP58-GXmkau0OLNoGcg?pwd=zp3o
Extraction code: zp3o
4) Debian 6 (Kali Linux)
Link: https://pan.baidu.com/s/1Uw6SXS8z_IxdkNpLr9y0zQ?pwd=s2i5
Extraction code: s2i5
Power-on password: jerry/123456
Installed Apache, Tomcat, MySQL, vsftpd and supporting Web security testing practice teaching plan.
start Tomcat
#/usr/local/apache-tomcat-8.5.81/bin/startup.sh
start MySQL
#service mysql start
start Apache
#/etc/init.d/apache2 start
Open a browser and enter 127.0.0.1:8080/sec/
5) Metasploitable2-Linux (with vsftpd 2.3.4)
Link: https://pan.baidu.com/s/1a71zOXGi_9aLrXyEnvkHwQ?pwd=17g6
Extraction code: 17g6
Power -on password : see the page prompt
After decompression, it is directly vmx file, which can be used directly
