
Authors: Even Oldridge, Karl Byleen-Higley
Translated by: Chen Zhiyan
Proofreading: zrx
This article is about 2500 words , it is recommended to read 10 minutes
This article shares with you a recommendation model that covers the entire process of deploying a recommender system.
The biggest challenge that novices face when building recommender systems is the lack of a tangible understanding of recommender systems, focusing most of the online content of recommender systems on models, and often limited to a simple collaborative filtering example. For new practitioners, there is a huge gap between simple model examples of recommender systems and real production systems.
This blog will share with readers a pattern that covers the entire process of deploying a recommender system, with sample programs from companies such as Meta, Netflix, and Pintery. This model is the core technology of the NVIDIA Merlin team to build an end-to-end system, and we are happy to share and promote it in the community to help readers build the concept and consensus of deploying recommender systems (not just models). If you are interested in content in this area, you can also attend a keynote speech organized by KDD's Industrial Recommender Systems workshop.
Looking Away Recommendation Model
What a recommendation model does, whether it's a simple collaborative filtering example, or a deep learning model like DLRM, is essentially a ranking, or more accurately, a scoring system where users are interested in a set of data item scoring. However, these scores by themselves are often insufficient to provide reasonable recommendations for users in the real world. Before exploring solutions and constructing the final recommender system, the following reasons will be investigated in depth.
The more data items, the more problems
The first problem encountered first is the number of data items in the recommendation. In extreme cases, data item records can be millions, hundreds of millions, or even billions. Scoring every data item is not feasible in most cases, and scoring is prohibitively expensive. In practice, you first need to quickly select a relevant subset of these items, such as scoring a thousand or ten thousand data items.
Entering the second stage, before scoring data items, it is necessary to select a reasonably relevant set that contains data items that users will eventually participate in. This stage is often referred to as the candidate retrieval stage, and may also be referred to as the candidate generation stage. Retrieval models come in many forms, including matrix factorization models, twin-tower models, linear models, approximate nearest neighbor models, and graph traversal models. In general, retrieval models are more computationally efficient than scoring models.
YouTube had an excellent paper in 2016 that was one of the first public references to the architecture, and now, the approach is widely adopted and widely used in the industry. EugeneYan has a great blog post on the subject, and his two-stage image was the inspiration for our four-stage recommendation graph, which is detailed below. It is worth noting that it is also common to use multiple candidate sources in the same recommender system to present different candidates to the user, and then save this topic to another blog.
Beyond the second stage!
Although a two-stage large-scale recommendation model can solve most problems, the recommender system also needs to support other constraints. In some scenarios, the user does not want to display certain data items, such as: when the data item is not in stock, when the age is inappropriate, when the user has already used the content, or when the user is not authorized to display it in the country, the user These data items are not intended to be displayed.
In addition to relying on scoring or retrieval models to infer business logic and recommend data items appropriately, a filtering stage needs to be added to the recommender system. Filtering is usually done after the retrieval stage and can be integrated with it (filtering ensures that there are enough candidates after retrieval), or even after scoring in some cases. The filtering phase applies business logic rules, and without filtering it would be impossible (or at least very difficult) for the model to enforce business logic rules. In some cases, filtering is simply an exclusion query, but in others it can be complex, like a Bloom filter, which can be used to remove data items that have already been interacted with by the user.
Sort!
Three stages have been introduced so far: retrieval, filtering, and scoring, which provide a list of data item suggestions and their corresponding scores, which represent the scoring model's guesses about how interesting the user is. Recommendation results are usually presented to users in the form of lists, which presents an interesting conundrum: the optimal list often does not exactly match the scores of the data items. Or even conversely, want to provide users with a completely different set of data items, show them items beyond recommended candidates, to explore spaces they haven't seen before, and prevent filter bubbles.
In some literature and examples, the third stage of recommender systems is called ranking, but showing the user the final ranking (or position) of the recommendation will rarely align directly with the output of the model, by providing an explicit ranking stage, it is possible to The output of the model is aligned with other requirements or constraints of the business.
Four-stage recommender system
Retrieval, filtering, scoring and sorting, these four stages constitute the design pattern of recommender system, which covers almost every recommender system. The diagram below shows the four stages and shows an example of how to build each stage. It is much more complex than a basic recommendation model, especially given the specific deployment of recommender systems, which accurately represents most of today’s volume. The architecture of the recommendation system.
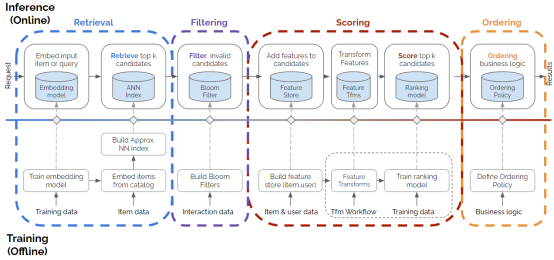
Example
With the description of the recommender system pattern, let's see how to build a recommender system. First, take a look at the common recsys task example, which at a high level covers the four-phase use case and demonstrates the four-phase unified pattern.
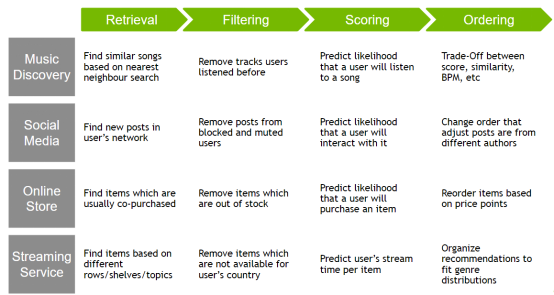
Going a step further, look at the example of a real-world recommender system to see if you can identify four stages.
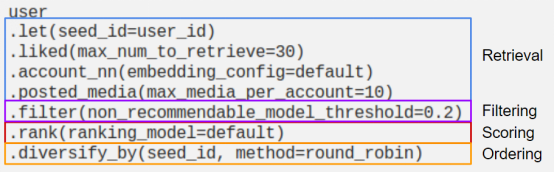
Meta's Instagram has a good article on the query language they developed - powered by AI: An Inquiry into Instagram's Recommender System (IGQL Query Language). From the examples they provide, this query language can be precisely mapped into the four phases of the recommendation schema:
Pinterest has published a series of papers (Pinterest related content: evolution of real-world recommendation systems, systematic recommendation of 300 million+ items and 200 million+ real-time users, deep learning related applications), one of which is a diagram in the first article, for The evolution of recommender system architectures over time is described. Here, we reproduce the same pattern, but with a subtle difference, treating retrieval and filtering as the same stage.
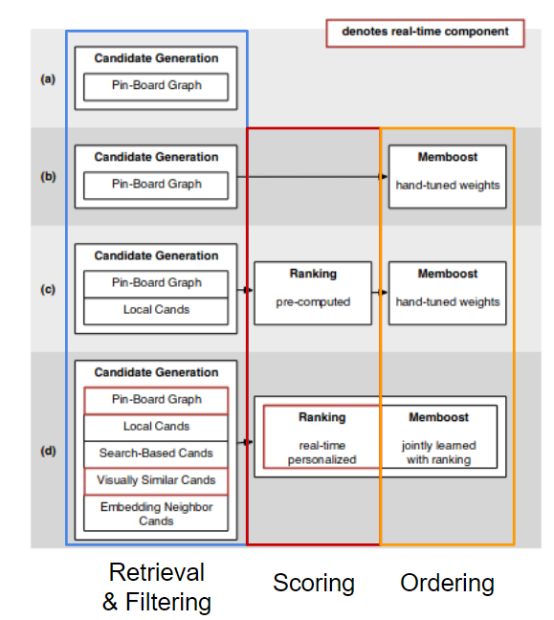
Instacart shared this architecture in 2016, with direct recommendations to follow four stages. Candidates are retrieved first, then previously sorted data items are filtered out, the most popular candidates are scored, and the final results are re-ranked to increase the variety of final results presented to the user.
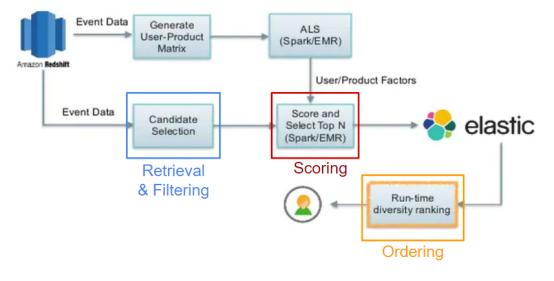
complex system
In the 4-stage diagram of this paper, the components required in the inference-time query process of training, deployment, and supporting full-stage are clarified. This system is much more complex than a single model, and those who search online for recommender system information and only find collaborative filtering models will be overwhelmed when they actually try to build a complex recommender system.
In the next blog post, I will delve into the details of this complex model and propose some solutions for the Merlin recommender system framework. Now I leave the challenge to you: interpreting and using the recommender system in detail, can you identify the four stages, and if so No, you can also communicate with us! We will continue to iterate and improve our ideas and libraries, striving to provide the best solution for the RecSys space, and we greatly appreciate your input.
Finally, if you are keen to build open source libraries to simplify the construction and deployment of recommender systems, welcome to communicate with you.
Recommender Systems, Not Just Recommender Models
https://medium.com/nvidia-merlin/recommender-systems-not-just-recommender-models-485c161c755e?source=explore---------12-98--------- -------------8159457e_aca6_4e87_a7ec_578a4e826171-------15
Proofreading: Yang Xuejun
Chen Zhiyan, graduated from Beijing Jiaotong University with a major in communication and control engineering, and obtained a master's degree in engineering. He has served as an engineer of Great Wall Computer Software and Systems Company, an engineer of Datang Microelectronics Company, and is currently the technical support of Beijing Wuyi Chaoqun Technology Co., Ltd. Currently engaged in the operation and maintenance of intelligent translation teaching system, he has accumulated certain experience in artificial intelligence deep learning and natural language processing (NLP). In his spare time, he likes to translate and create, and his translation works mainly include: IEC-ISO 7816, Iraqi Petroleum Engineering Project, Declaration of New Fiscalism, etc. Among them, the Chinese-English work "Declaration of New Fiscalism" was officially published in GLOBAL TIMES. I can use my spare time to join the translation volunteer group of the THU datapai platform. I hope to communicate and share with you and make progress together.
Translation team recruitment information
Job content: need a careful heart to translate selected foreign articles into fluent Chinese. If you are an international student of data science/statistics/computer, or are engaged in related work overseas, or have confidence in your foreign language level, you are welcome to join the translation team.
What you can get: regular translation training to improve the translation level of volunteers, improve the cognition of the frontier of data science, overseas friends can keep in touch with the development of domestic technology applications, THU data send industry-university-research background to bring good benefits to volunteers Development Opportunities.
Other benefits: Data scientists from famous companies, students from Peking University, Tsinghua University, and overseas famous universities will become your partners in the translation team.
Click " Read the original text " at the end of the article to join the data team~
Reprint notice
If you need to reprint, please indicate the author and source in a prominent position at the beginning of the article (from: Datapi ID: DatapiTHU), and place a datapi's eye-catching QR code at the end of the article. If there is an original identified article, please send [article name - name and ID of the official account to be authorized] to the contact email, apply for whitelist authorization and edit as required.
Please send the link feedback to the contact email address (see below) after publication. Unauthorized reprint and adaptor, we will investigate their legal responsibility according to law.
Click "read the original text" to embrace the organization
