I. Introduction to the Current Situation of Overseas Credit
Since the domestic financial P2P thunderstorm, many domestic small loan institutions have flooded into unexplored markets in Southeast Asia and Africa, such as Indonesia, India, the Philippines, Thailand, Vietnam, Nigeria and other countries.
Analyzing the market characteristics of these Southeast Asian/African countries, there are low financial inclusion (30.8% of people in Vietnam have a bank account in 2017), high demand for finance (49.0% of the population who borrowed in 2017) and Internet penetration (2018 66% in 2018) and mobile connectivity, providing the most favorable conditions for the development of fintech lending in Southeast Asia, opening a model of savage growth.
Combined with the loan market conditions in these regions, the construction of the credit reporting system and the economic situation are usually relatively poor, and most of the user qualifications are relatively poor (and do not meet the bank's loan qualifications). Under various factors, institutions have a poor grasp of the credit/fraud risks of lending users, and the bad debt rate of small loan institutions is generally high (for example, the bad debt rate of new loan users of some institutions can reach 20~30%, while the bad debt of banks is usually in the 10% or so).
The micro-loan products developed in Southeast Asia are generally 714 anti-aircraft guns (the loan cycle is 7-14 days, and high overdue fees are charged or the interest is deducted from the principal in advance when the loan is issued - the head-cut interest, and some actual annualized interest rates have reached 300%).
High interest rates inevitably carry high risks, and this kind of business is also easily blocked by financial regulatory policies.
2. Introduction to the Small Loan Risk Control System
With such a high bad debt situation, if small loan institutions are not sufficiently aware of the credit situation of borrowing users, even high interest rates may not cover such high credit risks.
It can be seen that the risk control capability is the core of the loss control of the small loan business. The risk control system usually consists of anti-fraud (document information verification, face recognition verification, blacklist) + application scoring model.
The key to the quality of risk control lies in the acquisition and accumulation of data. An obvious difference is that the bad debt rate of users with new loans in institutions is 20~30% (the proportion of fraudulent loan fraud should be quite high), while for old users who have refinanced loans in institutions (users who have previously borrowed and repeated loans) ) The bad debt rate is only 4%.
That is, for users whose institutions have mastered the loan history, the bad debt rate is significantly lower! The difference in credit risk control ability is actually the embodiment of the data monopoly advantage! For small loan institutions, after marketing to expand new users, how to apply the risk control model to evaluate new users as accurately as possible, and give a lower limit, and then increase the limit when they have a good credit history, and maintain and expand this part of the complex. Loan users are the key to business profitability.
The main sources of data for overseas small loan institutions to apply for the scoring model are:
-
Institutional historical loan records: such as the number of loan applications and overdue times using the same mobile phone number. In the case of incomplete coverage of the credit reporting system, the borrowing history within an institution (or a joint institution) is often the most convincing and effective. -
Basic customer information: such as identity information, contact information, occupation, income, loan purpose, etc. Since there is often no manual review of these data for online applications, the reliability of the information is doubtful, and it is usually possible to use multi-party data to verify whether these are consistent and reliable. -
Credit reporting agency's credit report: The world's three major commercial and personal credit reporting giants are Experian, Equifax and Trans union, which can provide loan application times, loan amount, credit account number and other information. However, the disadvantage is that for areas where the credit reporting system is not well established, the coverage and information records will be relatively poor (the actual coverage of Experian verified by this project is about 80%). -
Mobile SMS: SMS can provide a lot of valuable information, such as arrears, bank card income and expenditure, number of contacts, daily chat SMS, agency collection SMS, and the number of credit advertisements. Key features can be extracted through simple keyword matching, bag-of-words model and other methods, and further data such as the number of collected SMS messages, the amount of arrears, and the amount of income and expenditure can be counted through methods such as SMS classification and information extraction (entity extraction). The data is definitely not compliant. Institutions only want more data guarantees, but they don’t care about privacy data for users who are in a hurry to spend money. Currently, some apps have been banned from obtaining text messages and call records, which is also a matter of course. Regulations continue to improve.) -
Mobile phone address book: It can be used to count the overdue times and other characteristics of the associated contacts, as well as some other social information; -
APP data: The number of installed credit APPs, social APPs, and the app usage rate can be counted; -
Login IP, GPS, device number information: It can be used to correlate features, such as the number of overdue times under the same IP, and to establish IP and device blacklists; -
Bank statement data: such as salary flow and other information, can effectively reflect the user's repayment ability.
3. Application scoring model practice
3.1 Credit feature processing
This project is based on 500 recent micro-loan transactions in a country in Southeast Asia (data from the Internet, intrusion and deletion), obtains the corresponding Experian credit report data, and uses Python to process the credit characteristics of the sliding window: such as the number of loans in the past 30 days , the average loan amount, the latest loan date interval, the number of historical overdue and other characteristics, and build an application scoring model through LightGBM.
The modeling of this project is relatively simplified, and for a more complete scorecard modeling process, please refer to the previous article: This article sorts out the entire process of financial risk control modeling, A-card, lightgbm scorecard, chi-square binning, WOE coding and other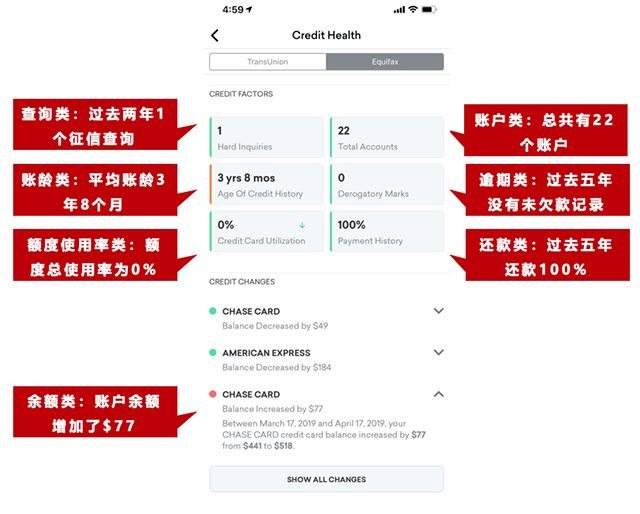 Experian credit reporting The original message of the report includes basic personal information, recent loan information, credit card, loan and other historical performance information. The following code slides the time window to extract the corresponding features.
Experian credit reporting The original message of the report includes basic personal information, recent loan information, credit card, loan and other historical performance information. The following code slides the time window to extract the corresponding features.
# 完整代码请关注公众号“算法进阶”或访问https://github.com/aialgorithm/Blog
def add_fea_grids(fea_dict, mult_datas, apply_dt='20200101', dt_key='Open_Date', calc_key="data['Amount_Past_Due']",groupfun=['count','sum', 'median','mean','max','min','std'], dt_grids=[7, 30,60,360,9999]):
"""
征信报告使用滑动时间窗口-近N天,加工字段A的 计数、平均、求和等特征.
fea_dict:最终特征存储的字典
mult_datas:多条的记录值
calc_key:数据特征字段的相对位置
"""
new_fea = {} # 记录各时间窗口的原始特征
for _dt in dt_grids:
new_fea.setdefault(_dt, [])# 按时间窗口初始化
fea_suffix = calc_key.split("'")[-2] + str(len(calc_key)) # 前缀备注
if mult_datas:
mult_datas = con_list(mult_datas)
for data in mult_datas:
if len(data[dt_key]) >=4 and data[dt_key] < apply_dt: #筛选申请日期前的记录,报告应该为准实时调用的
for _dt in dt_grids:
if (_dt==9999) or (ddt.datetime.strptime(str(data[dt_key]),"%Y%m%d") >= (ddt.datetime.strptime(str(apply_dt),"%Y%m%d") + ddt.timedelta(days=-_dt))) :# 筛选为近N天的记录,为9999则不做筛选
if "Date" in calc_key or "Year" in calc_key : #判断是否为日期型,日期直接计算为时间间隔
fea_value = diff_date(apply_dt, eval(calc_key) )
elif "mean" in groupfun: # 判断是否为数值型,直接提取到相应的时间窗
fea_value = to_float_ornan(eval(calc_key))
else:# 其他按字符型处理
fea_value = eval(calc_key)
new_fea[_dt].append(fea_value) # { 30: [2767.0, 0.0]}
for _k, data_list in new_fea.items(): # 生成具体特征
for fun in groupfun:
fea_name = fea_suffix+ '_'+ fun + '_' +str(_k)
fea_dict.setdefault(fea_name, [])
if len(data_list) > 0:
final_value = fun_dict[fun](data_list)
else :
final_value = np.nan
fea_dict[fea_name].append(final_value)

3.2 Feature selection
Considering the privacy of the credit report, this project only provides a sample report for feature processing. After feature processing, feature selection is performed, and overdue tags are associated to form the following final data feature wide table.
df2 = pd.read_pickle('filter_feas_df.pkl')
print(df2.label.value_counts()) # 逾期标签为label==0
df2.head()

3.3 Model training
train_x, test_x, train_y, test_y = train_test_split(df2.drop('label',axis=1),df2.label,random_state=1)
lgb = lightgbm.LGBMClassifier()
lgb.fit(train_x, train_y,
eval_set=[(test_x,test_y)],
eval_metric='auc',
early_stopping_rounds=50,
verbose=-1)
print('train ',model_metrics2(lgb,train_x, train_y))
print('test ',model_metrics2(lgb,test_x,test_y))
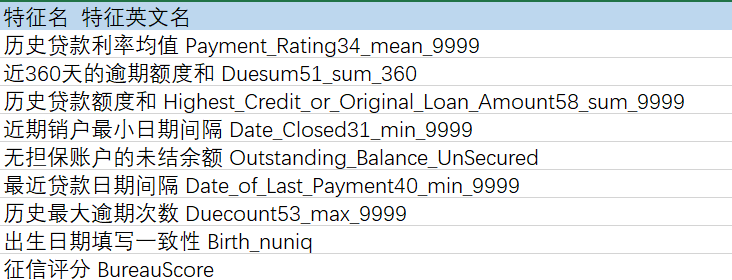
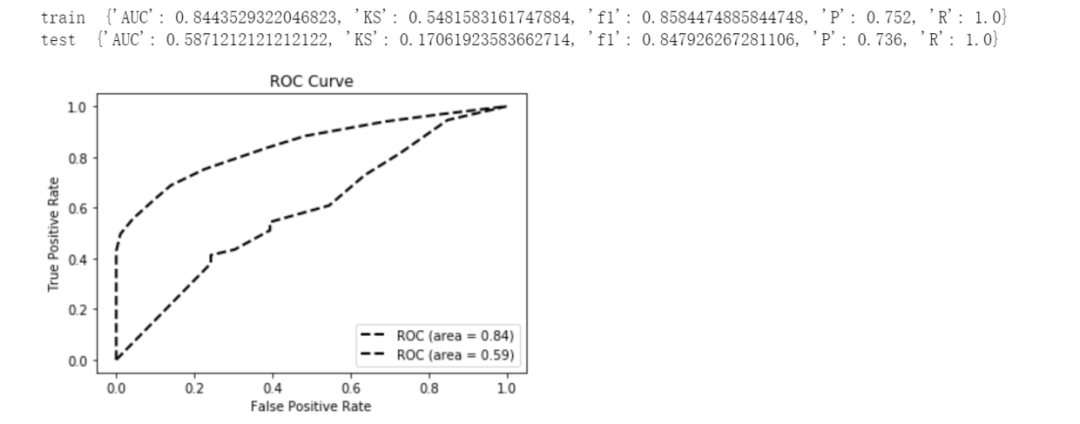 Using only the characteristics of the credit report data, it can be seen that the recognition effect for overdue users is very general, and the Test AUC is only about 60% (the follow-up still has to hope to add some SMS data, historical loan data, etc.). The important features of the comprehensive analysis model are:
Using only the characteristics of the credit report data, it can be seen that the recognition effect for overdue users is very general, and the Test AUC is only about 60% (the follow-up still has to hope to add some SMS data, historical loan data, etc.). The important features of the comprehensive analysis model are:
Reference link:
http://www.xinhuanet.com/fortune/2020-11/27/c_1126793844.htm
https://www.163.com/dy/article/H84VU3OR051196HN.html
https://zhuanlan.zhihu.com/p/ 88820665
END
Top 20 risk control text classification algorithms - character-level tfidf + logistic regression
The Vanishing Network - SpotLight, an Anomaly Detection Algorithm Based on Graph Flow
Credit card fraud isolation forest case study, optimal parameter selection, visualization, etc.
Isolation Forest, an algorithm for anomaly detection through XJB random segmentation
Listed company address similarity calculation & building relationship graph
Mining 'Typical Opinions' from Massive Texts - Text Clustering Based on DBSCAN
SynchroTrap - Fraudulent Account Detection Algorithm Based on Loose Behavior Similarity
Long press to follow this account Long press to add my friend
